Hello Everyone,
I had posted earlier in this site (on another sub forum) regarding my website getting hacked. Thanks to your advice I took steps to protect my server and its working fine now.
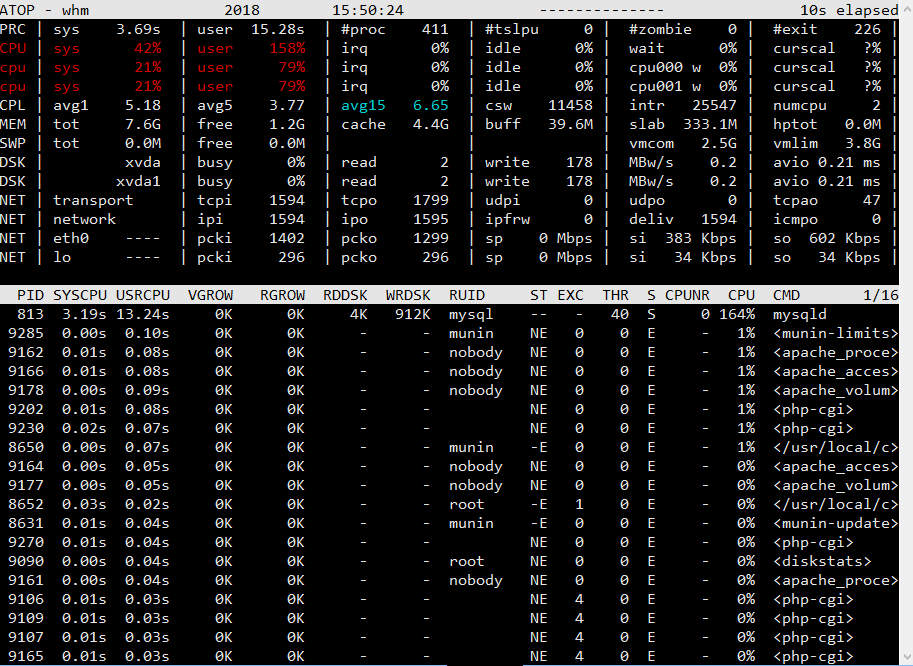
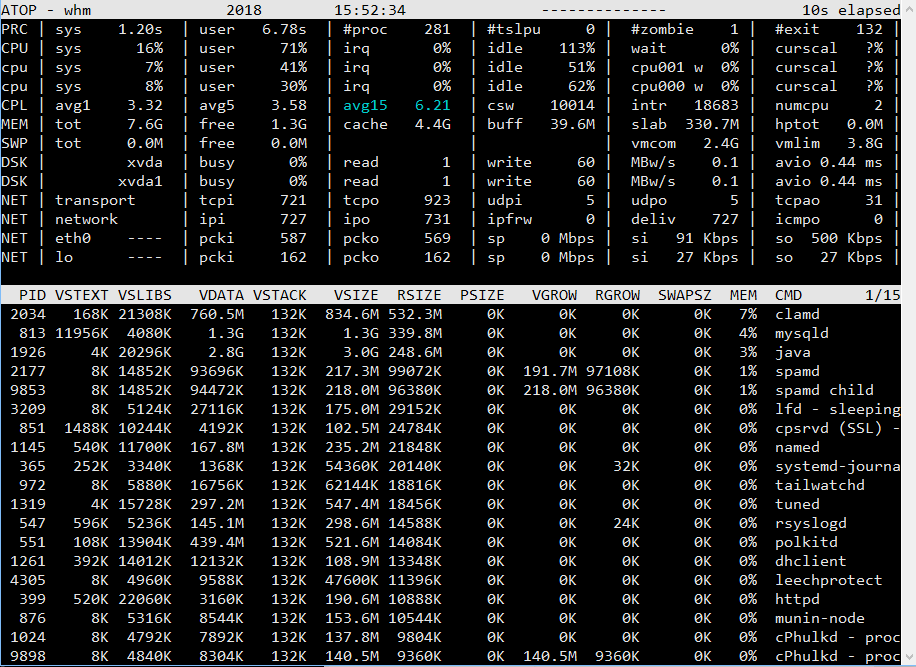
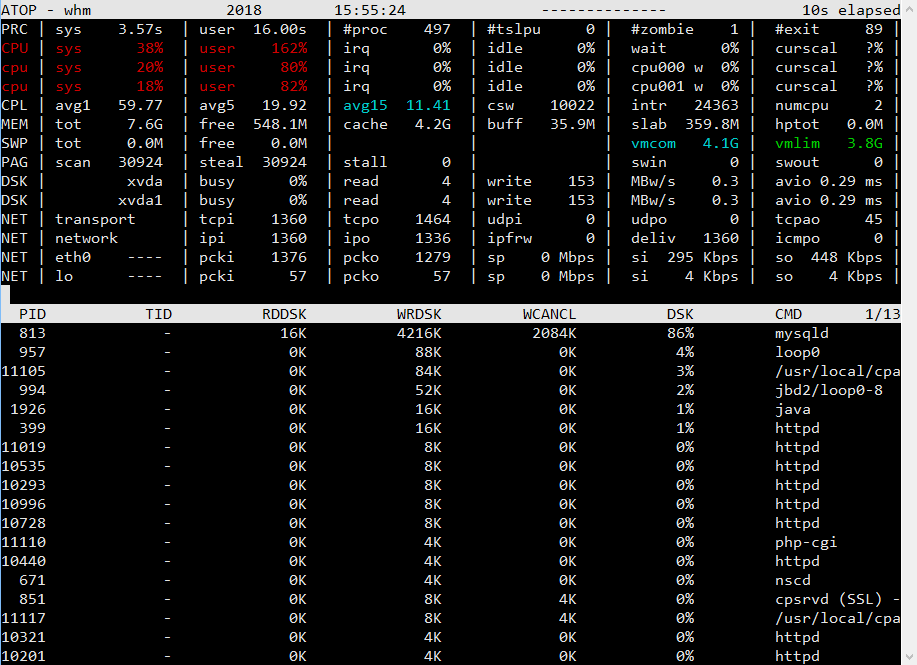
However now a new problem has come up. The server which runs my site is under heavy load. My website basically consists of the site itself, cms, blog and website apps. The website apps read some data from db and show it to users every 5 minutes. It is basically list of stocks and its related data.
I am running on AWS Platform, a t2.large server. My os is centos 7 and I run php, mysql, csf etc. The t2 has burstable cpu credits and at night the credits accumulate whichh are used by in day time. However the site starts slowing down if traffic increases. The cpu usage is high.
After some research I was told that I should shift to a M4 or C4 platform/server because t2 is meant for low traffic sites and development and not production. Moreover I may come up with mobile apps soon and if load increases it will be a problem.
What should I do? Should I go for M4 or C4 server in aws ?
Thank you,
Regards,
GR
I had posted earlier in this site (on another sub forum) regarding my website getting hacked. Thanks to your advice I took steps to protect my server and its working fine now.
However now a new problem has come up. The server which runs my site is under heavy load. My website basically consists of the site itself, cms, blog and website apps. The website apps read some data from db and show it to users every 5 minutes. It is basically list of stocks and its related data.
I am running on AWS Platform, a t2.large server. My os is centos 7 and I run php, mysql, csf etc. The t2 has burstable cpu credits and at night the credits accumulate whichh are used by in day time. However the site starts slowing down if traffic increases. The cpu usage is high.
After some research I was told that I should shift to a M4 or C4 platform/server because t2 is meant for low traffic sites and development and not production. Moreover I may come up with mobile apps soon and if load increases it will be a problem.
What should I do? Should I go for M4 or C4 server in aws ?
Thank you,
Regards,
GR

")