There's an argument for spreading out the heat generation a bit; supposing everything else is lined up properly, see AMD failing at this with their first HDM implementations, cooling is perhaps both less complicated and more efficient. AMD has also shown this with the Ryzen 3000 (Zen 2) series with a large cache/uncore die and up to two eight-core CPU dies in a pachage.
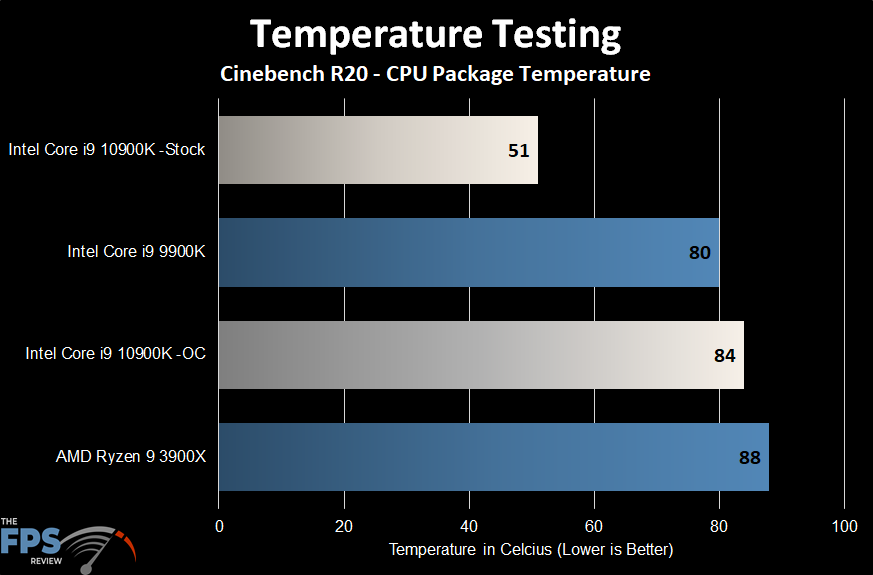
Current 10th gen Intel desktops, using significantly more power, still run at cooler temperatures than Ryzens, using less power with the same cooler. So I am not seeing this advantage. Here the OC 10900K is consuming ~70 Watts more than the Ryzen 9, and is running few degrees cooler. Single or multi-chip is near irrelevant difference in cooling.
Last edited:
")
