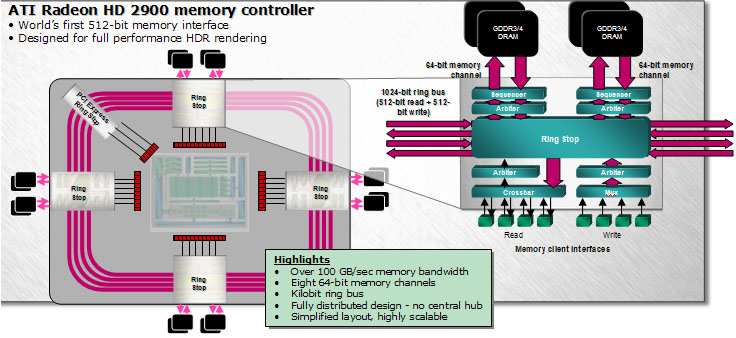
D
Deleted member 93354
Guest
Logically it isn't much different. You have independent units, with independent memory pools, with interconnects between them.
The devil is in the details. While NUMA is suitable for CPU use, it really isn't for Graphics. This paper isn't really about graphics at all.
Why do you think the memory pool are independent? Just because there is a direct link to a particular pool doesn't mean there isn't mechanisms in place to allow cross talk. There are unique memory architectures which allow for concurrent access for reads.
Snowdog, I think you have tunnel vision.