Aw, poor fella, forgot to mention that Intel parts cost twice as much and use more power than AMD parts. You have to resort to comparing core versus core, which not only is comparing a product to something 2x as expensive, but actually shows a WASH between the two when you look at ALL benchmarks, not just your favourites.
It must be tiring to be an Intel loyalist right now...
$599 is twice $499?
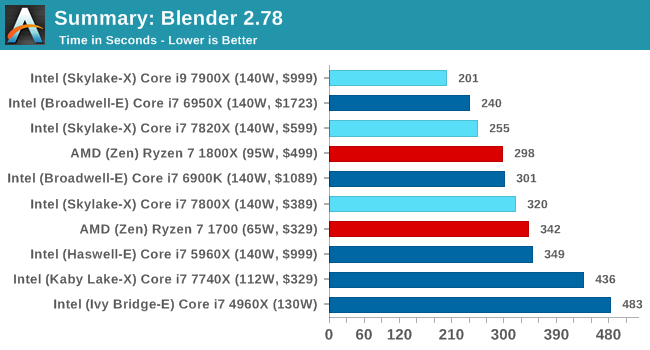
AMD compared 8-core RyZen to 8-core Broadwell in demos and slides. But comparing now 8-core vs 8-core get accusations of "tiring to be an Intel loyalist".
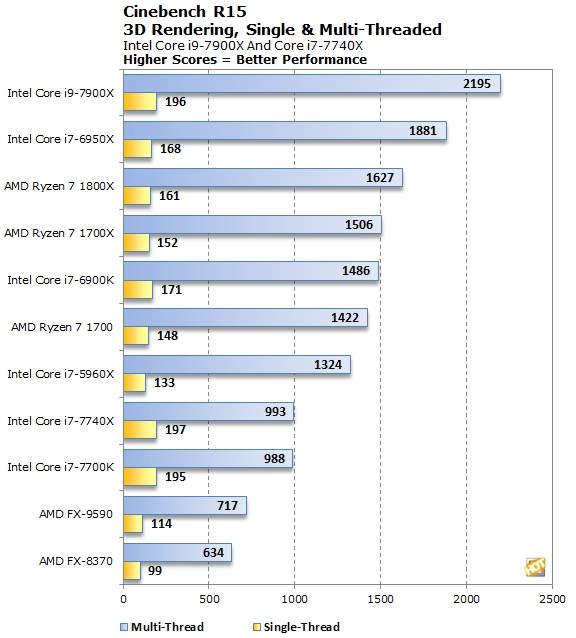
Cinebench, Blender, and Handbrake were tests used by AMD on Zen demos and slides. Now that AMD loses on all those benches, they are no valid benches anymore? Same happens with AoTs I guess.
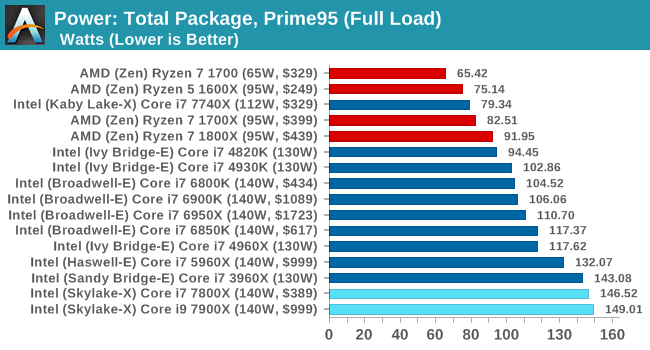
And yes, SKL-X consumes more power, because... it is faster.
Last edited:

")