Recently there have been some questions about the bonus system for SMP and bigadv WUs. I didn't really understand it either, so I did some research and decided to share it. I hope you don't minde the length. If you notice any mistakes, let me know.
Bonus Calculation
Stanford has certain work units that they would like to process quickly. The bonus system is designed to reward people with more powerful machines for running these work units. The bonus is not a fixed value but a multiplier. When you complete a work unit, you get the base points of the WU multiplied by the bonus factor. The faster a WU is completed, the larger the bonus factor. Here are the formulas:
WU_time is the time between being issued a WU by the Stanford servers and uploading the completed WU back to the servers. In other words, it is the calculation time plus the download and upload times. Timeout time, also known as the preferred deadline, is the time you have to complete a WU in order to receive a bonus. As the formula shows, if your WU_time is longer than the timeout time, your bonus factor is 1 and you only receive the base points. You must also have a client with a passkey and complete 10 units with at least 80% success to receive a bonus.
The last line shows how the bonus factor is calculated, and here it's helpful to look at some examples. But first, there's one more formula to consider, and that is Points Per Day. PPD is the total points per WU multiplied by the number of WUs that can be completed in a 24-hour day. The formula below assumes WU_time is in hours.
SMP Example
Information about individual work units is available on the Folding@Home Projects Summary page, and can also be displayed by monitoring tools like HFM.NET. Let's consider Project 6012, an A3 SMP work unit. The timeout time (preferred) is 3 days, the deadline is 6 days, the base point value (credit) is 470, and the K factor is 2.0. The K factor gives Stanford the ability to adjust the bonus factor for each WU.
First lets assume your hardware can just barely meet the deadline with a completion time of 3 days. If we plug that into the formula, you get:
At worst, you're still getting twice as many points per WU. Now let's say you have a overclocked i7 920 and can complete a P6012 WU in 6 hours. If we plug that into the formula, you get:
Now let's consider a high-end box. An SR-2 with two overclocked hex-core Xeons can complete the WU in 2 hours:
By now you should have noticed something. As the WU_time gets shorter, not only does the bonus increase, but you are also able to complete more WUs per day. That means the PPD is growing at an exponential rate. This is why high-end systems are such great producers under the bonus system. Normally, hardware scales linearly, meaning that if you want to double your PPD you have to double your hardware (build another CPU box, buy a second video card). However, the example SR-2 system above, which technically only has three times the hardware of the i7 box (12 cores vs. 4 cores) and is only completing the WUs three times faster, is earning more than 5 times the PPD.
bigadv
That was standard SMP, but what about bigadv? The formulas remain the same, but the values for the WUs are different. Currently all the A3 bigadv WUs have the following values: timeout is 4 days, deadline is 6 days, base credit is 8955, and K factor is 26.4. If we plug these values into the formulas with various WU_times, we get a nice chart:
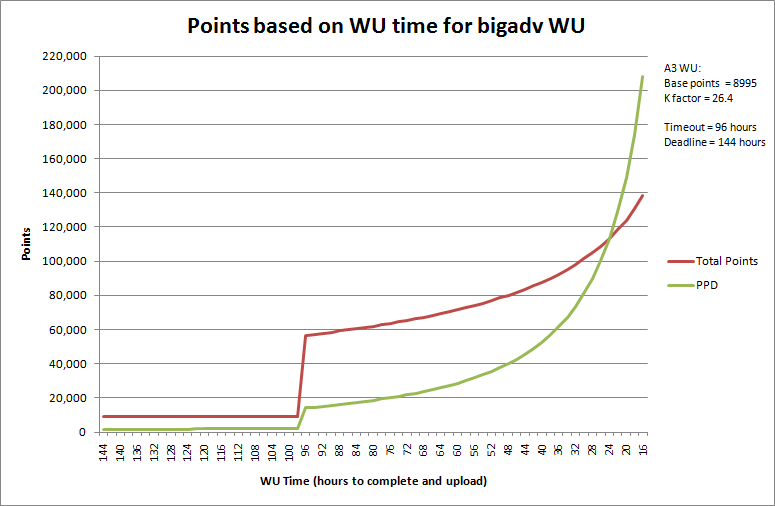
If the WU takes between 4 and 6 days to complete, there's no bonus so the points are really low. As soon as the bonus kicks in, the points are much higher thanks to the 26.4 K factor. Unlike the P6012 WU with a minimum bonus factor of 2, the bigadv bonus starts at 6.29. If you have hardware that can make the deadline, you can see how running bigadv can be worth it.
Using the example machines from before, say the quad-core i7 takes 60 hours to complete a bigadv WU. That gives a bonus factor of 7.96, total points of 71,599, and PPD of 28,640.
The 12-core SR-2 can complete the same WU in 20 hours, for a bonus factor of 13.79, total points of 124,014, and PPD of 148,816. Once again, the PPD is more than five times greater.
Conclusion
So, what is the takeaway from all of this? First, as already noted, point growth is no longer linear. This means hardware decisions are a little more complicated than just adding more boxen. With a limited budget, maybe investing in a Gulftown 970 or 980X makes more sense than building a second cheap box or buying a high-end GPU. For large farms, the SR-2 with hex-cores or similar high-end multiprocessor hardware may make sense, especially compared to the power cost of GPU farms.
The exponential nature of bonuses also means a relatively small increases in speed can have a big impact on points, especially with high-end hardware. Therefore, optimizing the hardware you have to run SMP as fast as possible is important. For example, this can means finding the maximum stable overclock of your CPU, using Ethernet instead of wireless to speed up transfer times, avoiding processes that steal CPU cycles, and even dedicating the box to F@H so that it's always "idle." GPU folding on an SMP machine should be examined to make sure that the GPU points more than make up for the lost SMP points. There will always be compromises and other considerations like power usage, not to mention the desire to use your most powerful machine for gaming, etc. (I still plan to use my SR-2 as my primary desktop.) However, you may want to keep a log of PPD for various hardware configurations and usage scenarios, to see how your real-world PPD compares with the charts and formulas.
Finally, although the steep curve at the right end of the graph above is tempting, and the bonus is theoretically unlimited, there are practical considerations. The graph stops at 16 hours because that's the fastest bigadv completion time of which I'm aware. To put that in perspective, that equates to a time per frame of 9:36, and probably means either 16 very fast cores or 24 to 32 slower cores. In other words, for every hour you try to shave off your bigadv WU time, there's probably an exponential growth to cost as well as PPD. Enterprise grade hardware is very expensive, and super high-end enthusiast hardware (a watercooled SR-2 for example) isn't much cheaper. In addition to budget considerations, remember that no matter how fast your box is, when it's offline it is generating zero PPD. In other words, you may not want to put all your eggs in one basket.
Notes/Resources
The examples above are intended to be realistic, but I used round numbers to keep the math simple. In the real world, you'll be folding different WUs with varying performance characteristcs. In other words, don't expect 148K PPD from an SR-2 unless you have a killer overclock. For real-world numbers take a look at musky's excellent The Best Way to 100K PPD thread, which also covers PPD/$ and PPD/W.
The formulas come from this FAQ on the Folding Forum. Note that originally there was a maximum bonus factor of 10, but that has been removed. I graphed it both ways and was somewhat surprised to see that PPD still has exponential growth even with a capped bonus, but the growth rate is slower.
Edit: I created a Google spreadsheet for those who would like to explore the data on their own.

Bonus Calculation
Stanford has certain work units that they would like to process quickly. The bonus system is designed to reward people with more powerful machines for running these work units. The bonus is not a fixed value but a multiplier. When you complete a work unit, you get the base points of the WU multiplied by the bonus factor. The faster a WU is completed, the larger the bonus factor. Here are the formulas:
Code:
Total points = base points * bonus factor
If WU_time > timeout time, bonus factor = 1
If WU_time <= timeout time, bonus factor = sqrt(deadline_time * K / WU_time)WU_time is the time between being issued a WU by the Stanford servers and uploading the completed WU back to the servers. In other words, it is the calculation time plus the download and upload times. Timeout time, also known as the preferred deadline, is the time you have to complete a WU in order to receive a bonus. As the formula shows, if your WU_time is longer than the timeout time, your bonus factor is 1 and you only receive the base points. You must also have a client with a passkey and complete 10 units with at least 80% success to receive a bonus.
The last line shows how the bonus factor is calculated, and here it's helpful to look at some examples. But first, there's one more formula to consider, and that is Points Per Day. PPD is the total points per WU multiplied by the number of WUs that can be completed in a 24-hour day. The formula below assumes WU_time is in hours.
Code:
PPD = total points * 24 / WU_timeSMP Example
Information about individual work units is available on the Folding@Home Projects Summary page, and can also be displayed by monitoring tools like HFM.NET. Let's consider Project 6012, an A3 SMP work unit. The timeout time (preferred) is 3 days, the deadline is 6 days, the base point value (credit) is 470, and the K factor is 2.0. The K factor gives Stanford the ability to adjust the bonus factor for each WU.
First lets assume your hardware can just barely meet the deadline with a completion time of 3 days. If we plug that into the formula, you get:
Code:
bonus = sqrt( (6*24) * 2.0 / (3*24) ) = [B]2[/B]
total points = 470 * 2 = [B]940[/B]
PPD = 940 * 24 / (3*24) = [B]313[/B]At worst, you're still getting twice as many points per WU. Now let's say you have a overclocked i7 920 and can complete a P6012 WU in 6 hours. If we plug that into the formula, you get:
Code:
bonus = sqrt( (6*24) * 2.0 / 6 ) = [B]6.928[/B]
total points = 470 * 6.928 = [B]3256[/B]
PPD = 3256 * 24 / 6 = [B]13,024[/B]Now let's consider a high-end box. An SR-2 with two overclocked hex-core Xeons can complete the WU in 2 hours:
Code:
bonus = sqrt( (6*24) * 2.0 / 2 ) = [B]12[/B]
total points = 470 * 12 = [B]5640[/B]
PPD = 5640 * 24 / 2 = [B]67,680[/B]By now you should have noticed something. As the WU_time gets shorter, not only does the bonus increase, but you are also able to complete more WUs per day. That means the PPD is growing at an exponential rate. This is why high-end systems are such great producers under the bonus system. Normally, hardware scales linearly, meaning that if you want to double your PPD you have to double your hardware (build another CPU box, buy a second video card). However, the example SR-2 system above, which technically only has three times the hardware of the i7 box (12 cores vs. 4 cores) and is only completing the WUs three times faster, is earning more than 5 times the PPD.
bigadv
That was standard SMP, but what about bigadv? The formulas remain the same, but the values for the WUs are different. Currently all the A3 bigadv WUs have the following values: timeout is 4 days, deadline is 6 days, base credit is 8955, and K factor is 26.4. If we plug these values into the formulas with various WU_times, we get a nice chart:
If the WU takes between 4 and 6 days to complete, there's no bonus so the points are really low. As soon as the bonus kicks in, the points are much higher thanks to the 26.4 K factor. Unlike the P6012 WU with a minimum bonus factor of 2, the bigadv bonus starts at 6.29. If you have hardware that can make the deadline, you can see how running bigadv can be worth it.
Using the example machines from before, say the quad-core i7 takes 60 hours to complete a bigadv WU. That gives a bonus factor of 7.96, total points of 71,599, and PPD of 28,640.
The 12-core SR-2 can complete the same WU in 20 hours, for a bonus factor of 13.79, total points of 124,014, and PPD of 148,816. Once again, the PPD is more than five times greater.
Conclusion
So, what is the takeaway from all of this? First, as already noted, point growth is no longer linear. This means hardware decisions are a little more complicated than just adding more boxen. With a limited budget, maybe investing in a Gulftown 970 or 980X makes more sense than building a second cheap box or buying a high-end GPU. For large farms, the SR-2 with hex-cores or similar high-end multiprocessor hardware may make sense, especially compared to the power cost of GPU farms.
The exponential nature of bonuses also means a relatively small increases in speed can have a big impact on points, especially with high-end hardware. Therefore, optimizing the hardware you have to run SMP as fast as possible is important. For example, this can means finding the maximum stable overclock of your CPU, using Ethernet instead of wireless to speed up transfer times, avoiding processes that steal CPU cycles, and even dedicating the box to F@H so that it's always "idle." GPU folding on an SMP machine should be examined to make sure that the GPU points more than make up for the lost SMP points. There will always be compromises and other considerations like power usage, not to mention the desire to use your most powerful machine for gaming, etc. (I still plan to use my SR-2 as my primary desktop.) However, you may want to keep a log of PPD for various hardware configurations and usage scenarios, to see how your real-world PPD compares with the charts and formulas.
Finally, although the steep curve at the right end of the graph above is tempting, and the bonus is theoretically unlimited, there are practical considerations. The graph stops at 16 hours because that's the fastest bigadv completion time of which I'm aware. To put that in perspective, that equates to a time per frame of 9:36, and probably means either 16 very fast cores or 24 to 32 slower cores. In other words, for every hour you try to shave off your bigadv WU time, there's probably an exponential growth to cost as well as PPD. Enterprise grade hardware is very expensive, and super high-end enthusiast hardware (a watercooled SR-2 for example) isn't much cheaper. In addition to budget considerations, remember that no matter how fast your box is, when it's offline it is generating zero PPD. In other words, you may not want to put all your eggs in one basket.
Notes/Resources
The examples above are intended to be realistic, but I used round numbers to keep the math simple. In the real world, you'll be folding different WUs with varying performance characteristcs. In other words, don't expect 148K PPD from an SR-2 unless you have a killer overclock. For real-world numbers take a look at musky's excellent The Best Way to 100K PPD thread, which also covers PPD/$ and PPD/W.
The formulas come from this FAQ on the Folding Forum. Note that originally there was a maximum bonus factor of 10, but that has been removed. I graphed it both ways and was somewhat surprised to see that PPD still has exponential growth even with a capped bonus, but the growth rate is slower.
Edit: I created a Google spreadsheet for those who would like to explore the data on their own.
Last edited:

