Navigation
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
More options
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Anyone make the switch from 5800X3D to 7800X3D?
- Thread starter KickAssCop
- Start date
MistaSparkul
2[H]4U
- Joined
- Jul 5, 2012
- Messages
- 3,524
Ahh I misread the post and voted.
I read 5800x and not x3d sorry. I did switch from 5800x to 7800x3d though.
I just bought parts from Microcenterbw days ago. I will build the sys this week
I'm sure its gonna absolutely blaze in games.
I upgraded from a 5800X to a 7800X3D and the uplift is totally noticeable when you are CPU limited (which can happen even at 4K on a 4090). It's a gaming beast and you'll love it.
I was originally planning to skip this generation - but I wanted to go to 128gb of ram for AI inference and didn't want to invest more in AM4. I already have some use cases that benefit from 16 cores, though not enough to make me upgrade originally to a 7950x3d, and still game quite a bit, so going to make the jump now that price has dropped. As a side bonus, DDR5 provides a big jump in AI inference speed when using CPU - 8700G (which is ostensibly slower) is over 50% faster than my 5800x3d in AI inference. It should give me a meaningful gain in everything I currently do, so seems like the time is right - and I can always drop in next gen x3d when it releases.
Gideon
2[H]4U
- Joined
- Apr 13, 2006
- Messages
- 3,558
I am curious, what program are you running that requires AI work?I was originally planning to skip this generation - but I wanted to go to 128gb of ram for AI inference and didn't want to invest more in AM4. I already have some use cases that benefit from 16 cores, though not enough to make me upgrade originally to a 7950x3d, and still game quite a bit, so going to make the jump now that price has dropped. As a side bonus, DDR5 provides a big jump in AI inference speed when using CPU - 8700G (which is ostensibly slower) is over 50% faster than my 5800x3d in AI inference. It should give me a meaningful gain in everything I currently do, so seems like the time is right - and I can always drop in next gen x3d when it releases.
I am curious, what program are you running that requires AI work?
I'm using LM studio to host local models and TaskWeaver and/or OpenInterpreter for interactions - basically having them write and test code for different tasks. I work in the AI/ML space and we can't use remotely hosted models due to data sharing concerns so being able to test them locally helps me assess feasibility. I've found that an agent setup using specialized models can get close to GPT 3.5 performance, but not GPT4. To get it working well enough to be usable requires multiple models running at once for inference - essentially use a specialized language one for planning out a task, a specialized code model for writing the code, and others as needed.
Last edited:
I'm using LM studio to host local models and TaskWeaver and/or OpenInterpreter for interactions - basically having them write and test code for different tasks. I work in the AI/ML space and we can't use remotely hosted models due to data sharing concerns so being able to test them locally helps me assess feasibility. I've found that an agent setup using specialized models can get close to GPT 3.5 performance, but not GPT4. To get it working well enough to be usable requires multiple models running at once for inference - essentially use a specialized language one for planning out a task, a specialized code model for writing the code, and others as needed.
Is AI performance a metric of speed?
chameleoneel
Supreme [H]ardness
- Joined
- Aug 15, 2005
- Messages
- 7,604
I meant to post this a couple months ago. This seems like kind of a general thread for X3D now?
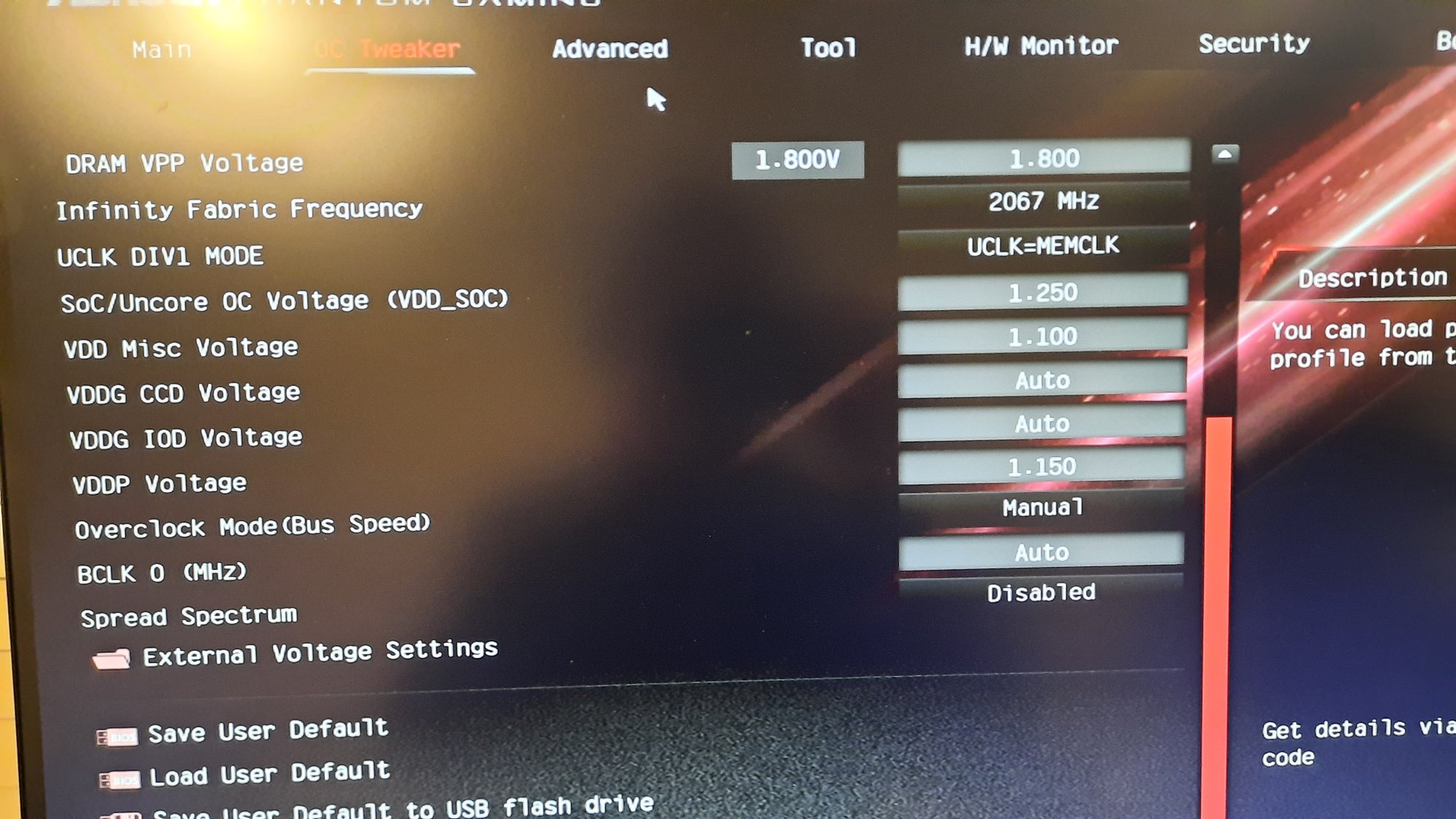
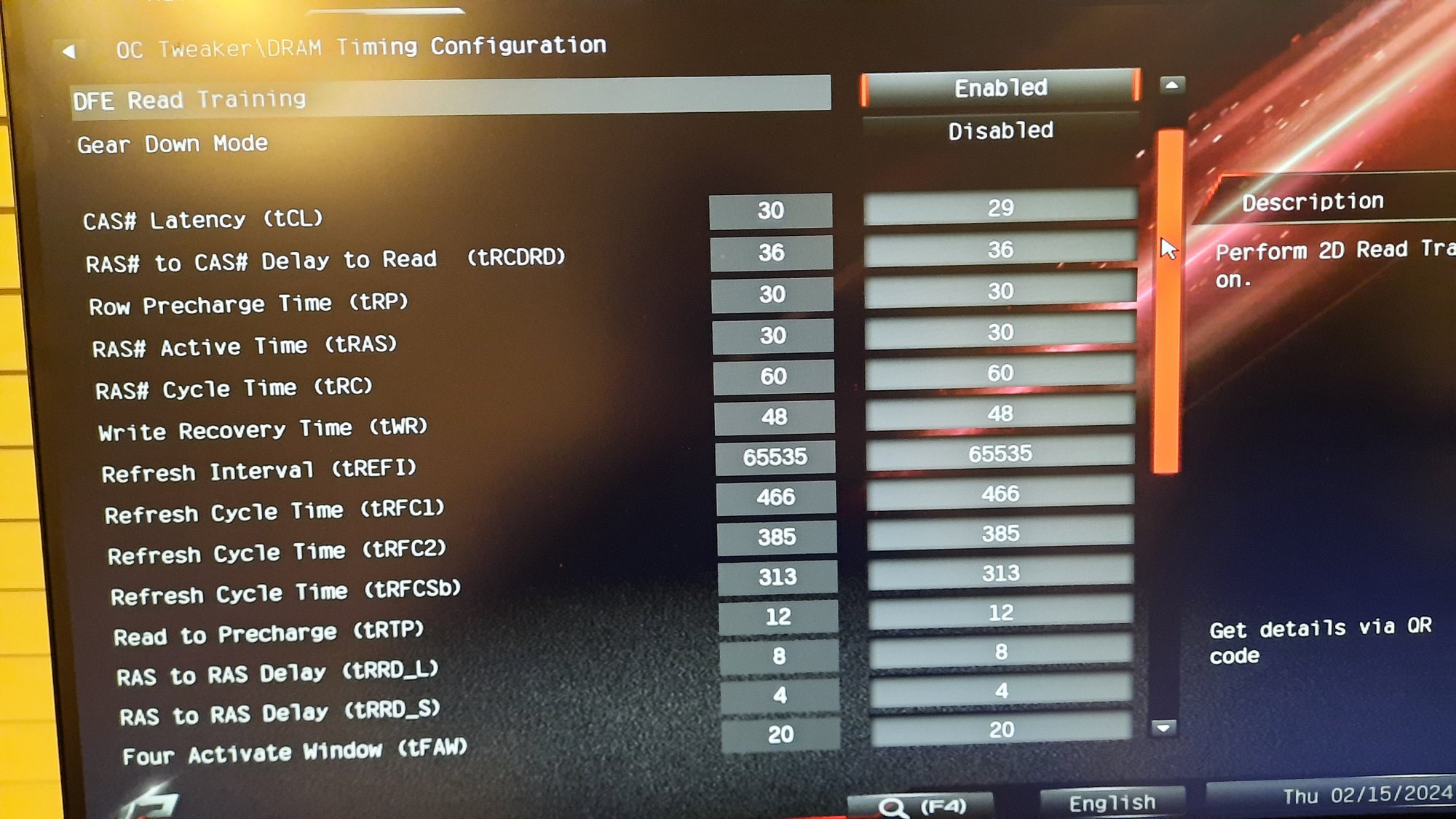
Anyway, it's my RAM settings. T-Create Expert DDR5 7200 sticks @ DDR5 6200 1:1 ratio.
Started with buildzoids timings used in Hardware Unboxed's Zen 4 memory tuning video----and then I watched a couple of Buildzoid's own videos dated after that HUB video, and adapted some updated timings from it.
This has been absolutely stable. No crashes or weirdness. Passes every test I can muster. Including Buildzoids favorite, Linpack.
Anyway, it's my RAM settings. T-Create Expert DDR5 7200 sticks @ DDR5 6200 1:1 ratio.
Started with buildzoids timings used in Hardware Unboxed's Zen 4 memory tuning video----and then I watched a couple of Buildzoid's own videos dated after that HUB video, and adapted some updated timings from it.
This has been absolutely stable. No crashes or weirdness. Passes every test I can muster. Including Buildzoids favorite, Linpack.
Attachments


funkydmunky
2[H]4U
- Joined
- Aug 28, 2008
- Messages
- 3,880
Sweet. Thanks for the input!I upgraded from a 5800X to a 7800X3D and the uplift is totally noticeable when you are CPU limited (which can happen even at 4K on a 4090). It's a gaming beast and you'll love it.
Is AI performance a metric of speed?
You can measure performance on a large language model in initial response time and tokens per second. I did a bunch of testing on hardware I have and will test the 7950x3d when it gets here this weekend:
Asus G14 (16gb lpddr4 3200mhz)
4900HS IGP (Vega 8CU) 1.5 tok/s
4900HS CPU (Zen 2 8 cores) 7 tok/s
RTX2060 maxq 8 tok/s
AM4 (32 gb ddr4 3000mhz)
5800x3d 8 tok/s
AM5 (64gb ddr5 6000mhz)
8700G IGP (RDNA3 12CU) 5 tok/s
8700G CPU (Zen4 8 cores) 14 tok/s
RTX4090 80 tok/s
Mac M1Pro 16gb
IGP 14 tok/s
CPU 7 tok/s
Initial response time mostly followed tokens/s except for Mac CPU which had a huge initial response time. Not sure if that's a quirk with LM Studio, which is what I was using to host or what, but in any case as the IGP has full access to all system ram, you'd always use the IGP. Tok/s varies somewhat based on model and context size, but they were tested with similar models that could fit entirely into addressable ram (ie less than 6gb for the 2060 and 8gb for the Vega8). Tokens/s basically how fast the model can type, multiply by 6 to get roughly words/minute. 15 tok/s roughly usable for question/response, but if you want them to be autonomous agents doing work, the faster the better.
If the 7950x3d can maintain a 15tok/s or higher performance with really big models, it could very powerful as it'd let you use 70B parameter models with large context size. A threadripper pro with octo channel ram would be really interesting to see in this context as they could really fly if performance scales more with ram bandwidth....I'm not curious enough to spend $3k to find out, though, as I have nothing else that would need the ram or cpu power and it'd hurt performance in games, where the 7950x3d doesn't compromise at all on the stuff I do most.
KickAssCop
[H]F Junkie
- Joined
- Mar 19, 2003
- Messages
- 8,331
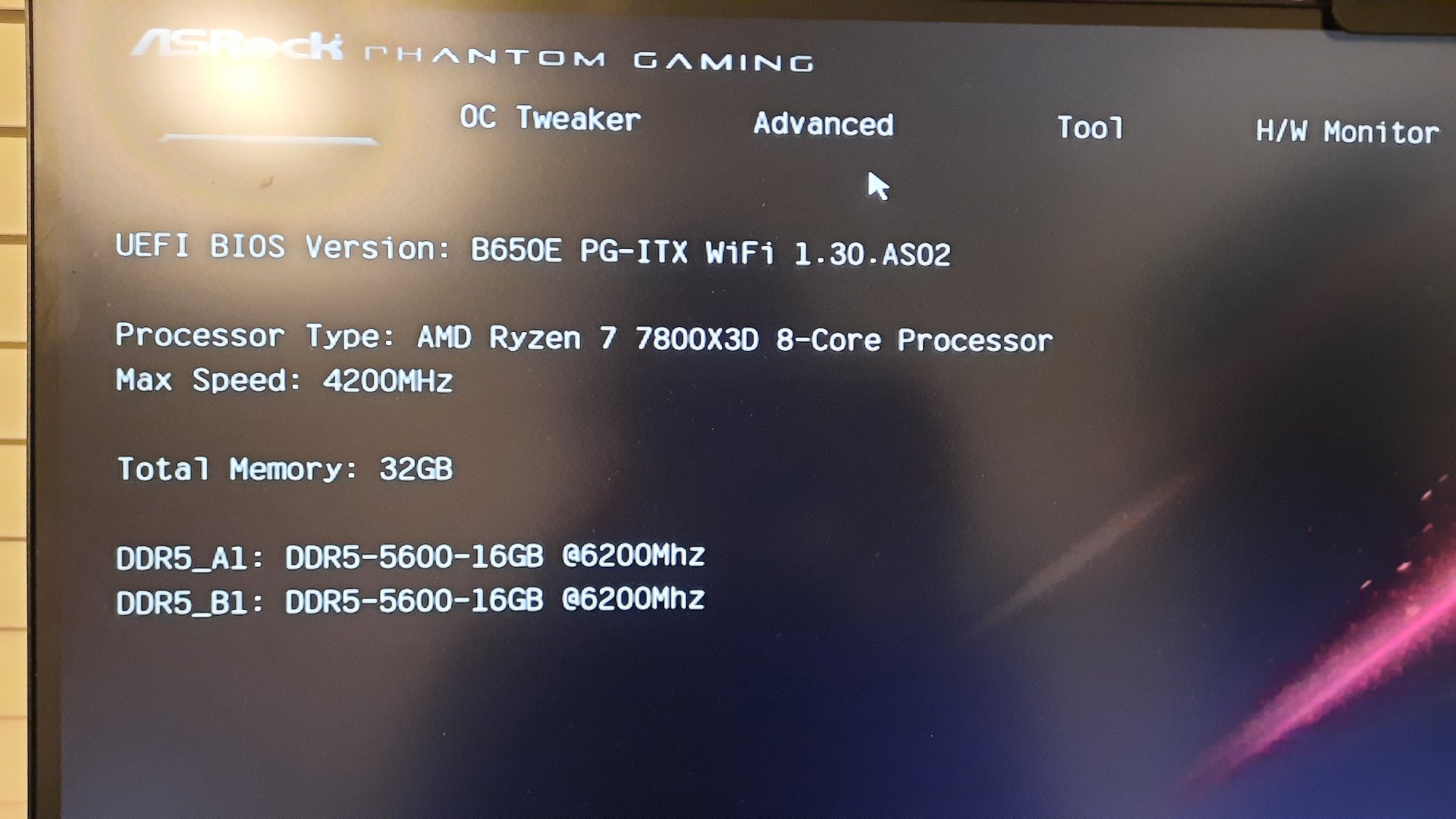
Set memory to 6200 and FCLK to 2067. Slightly higher scores in benches. Yay.