Pieter3dnow
Supreme [H]ardness
- Joined
- Jul 29, 2009
- Messages
- 6,784
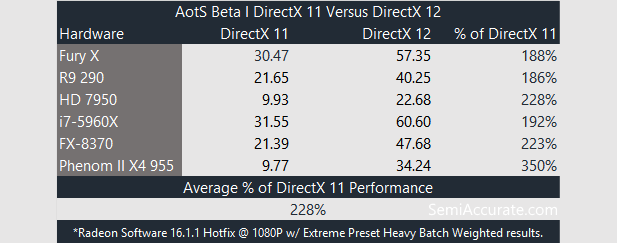
There is not a single DX 12 Benchmark where a FX beats an i3. Cores are good to have but are not needed. IPC is needed for sure.
No but there are plenty of Mantle Star Swarm results which suggest that you can take your IPC and stick it ...

")