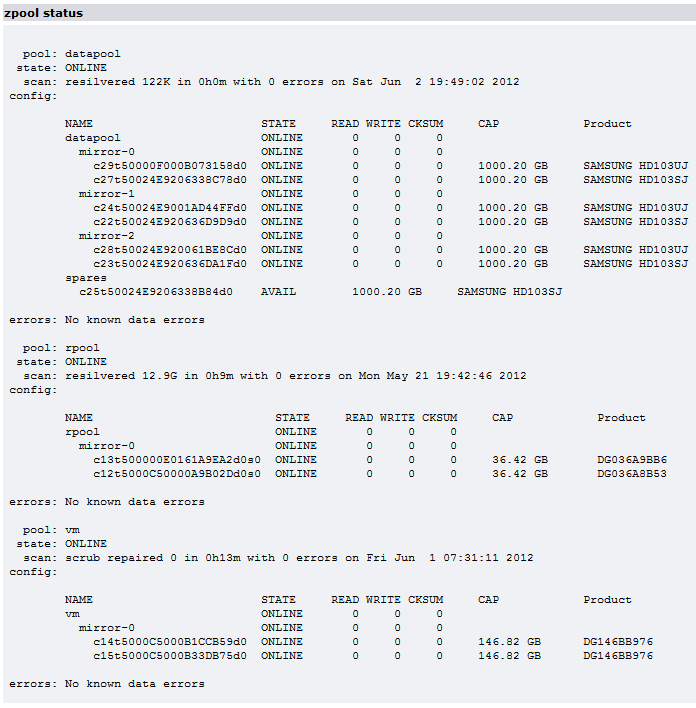
Hey,
Found an update for my Samsung F3 HD103SJ drives here. I know it is to fix a different problem, but my desperation level is incredibly high, so I'll try it anyway. I was too upset yesterday to try this, so I'll give it a shot this weekend. Also, I have not yet checked if my drives already have this FW level.
However, I did not find for the life of me an update for my Samsung F1 HD103UJ drives. So this whole thing might not really do something, but calming my mind knowing that I tried everything possible.
Unfortunately, I never paid attention which of the drives is failing when it does - the F1 or the F3's. I will note that in future events, which I'm sure by now they will reoccur.
What also hits me by now is that I never had *any* problems whatsoever on my rpool (both SATA Seagate and now SAS Fujitsu drives) or the VM pool (also both SATA Seagate and now SAS Fujitsu drives). It's always my datapool with the Samsung drives.
So how are my drives connected? At the moment, they're connected onboard (LSI SAS2008 Controller) with forward breakout cables, 50cm long, SFF-8087 to 4 x SATA. It's the second set I am trying, they're from Supermicro and should therefore fit perfectly the Supermicro mainboard with the onboard LSI controller. I have the same cables but 70cm in length to the SAS drives from my 9211-8i controller, and they work perfectly there, even though I use two Raidsonic backplanes for SAS.
If I see an error (means if I can still connect to the console), it's simply "too many errors" on one or several disks. In the past, I could often not connect anymore, which did not happen anymore since I turned off multipath. When I hit "clear errors", it resets everything, so it will show me S:0 H:0 T:0 afterwards... I checked the log yesterday, and it began with the same like last time, but this time for target 13, so I guess it's not really following a pattern. Then it later said "too many errors" on a device and turned it off, taking the spare into duty.
Best regards,
Cap'
Captain,
I sooo understand the level of frustration you're feeling. I'll have a pint in your honour! Okay, maybe three.
I have seen the firmware update you found. As all my drives are of the firmware excluded I've yet to attempt to flash. The documentation says the flash will fail on drives with a certain firmware.
I've 1m cables due to the size of my case. I thought, perhaps, the cable length may be causing a bit of problems.
When the spare is activated see what errors are shown. All that I see are transport errors. You're able to clear the faults for a certain time. Once the drive goes offline, only a hard reboot will clear it. Even going to init 6 doesn't clear the counters. It may be a function of the quick reboot.
Looking through the mptsas source the time out error is thrown when a scsi-reset times out. So one wonders whether the controller hangs when executing the reset or the drive isn't responding fast enough. Some data from SMART indicates when it comes out of sleep - I can't recall if they're errors or just counters. I tried a while back disabling power management thinking the drives may be going to sleep and then don't come back fast enough. I didn't really notice a difference. Before I migrated other services to this box it would sit idle most of the night. I noticed then drives would go off line once the load increased on the pool.
I've moved my pool of samsungs to the on-board sata and left one drive on the sas controller with the system disk. I'll see how this goes.
When I imported the pool it couldn't locate the hot spare. So I removed it and went to add it with the sata name and *bam* kernel panic. I've yet to go through the dump with mdb but after a restart I was able to add the drive no problem. It's also one of the drives that gives the most problems.
I'm going to fire-off some emails to LSI and Seagate and see if I can find any more info. I'm not holding my breath with Seagate. I am hoping, though, that some dev at LSI goes, "wait, I know what this is!" One can only hope.
I'll let you know how those pints taste
")
Cheers,
Liam