Navigation
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
More options
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
OpenSolaris derived ZFS NAS/ SAN (OmniOS, OpenIndiana, Solaris and napp-it)
- Thread starter _Gea
- Start date
A newer napp-it is faster than an older due optimized reading of ZFS properties.Interestingly, the interface is significantly quicker now; for example clicking on ZFS Filesystems and the list populating in less than 3sec rather than about 15sec before.
Another reason may be enabled acceleration (read properties in the background), see toplevel menu near logout.
Hi Gea,
Have you used OmniOS as torrent server? Currently I'm using transmission, but the program hangs if the download speed is too fast. Do you recommend any good program that can handle fast download speed?
Thanks
I have never tried one. You may use one on a Linux LX container.
Hi again,
As mentioned above in my overly long post about 10G speeds: CPU usage seems high when idle: ESXi is now reporting average 30% for 2x vCPU and 45% for 1 vCPU (network & disk near 0%)
Other ESXi VMs are near 0% CPU when idle.
Pools are not currently being accessed: no VMs, file transfers, no jobs running, I have disabled: auto-service, iSCSI, SMB and NFS. It was also like this before my recent reinstall.
The little napp-it CPU monitor is green, most processes are near 0%, except for the 'busy (iostat): last 10s' is between 20-100% and typically about 40%.
The napp-it VM has 93 filesystems across 3 pools: 3x NVMe vmdk Z1 / 6x 8TB HDD RAID10 / 8x 3TB HDD Z2, 2x vmxnet3
Memory 48Gb, CPU is Xeon E-2278G 8-core, base 3.4Ghz, boost 5Ghz
What is it processing? is this typical for OmniOS?
Under menu Extensions > Realtime Monitor > should I see some activity?
Edit: It appears to be mostly the interface, as it eventually dropped to 10-15%, a short while after I logged off from from napp-it webgui.
I left napp-it running (logged off) while I was away and then logged back on about 10mins ago, as the ESXi screen grab below.
So for my system, 1x vCPU usage is 10-15% when idle and logged off, and up to 45% when logged on.

BBQ quote "If you're looking, you ain't cooking"
As mentioned above in my overly long post about 10G speeds: CPU usage seems high when idle: ESXi is now reporting average 30% for 2x vCPU and 45% for 1 vCPU (network & disk near 0%)
Other ESXi VMs are near 0% CPU when idle.
Pools are not currently being accessed: no VMs, file transfers, no jobs running, I have disabled: auto-service, iSCSI, SMB and NFS. It was also like this before my recent reinstall.
The little napp-it CPU monitor is green, most processes are near 0%, except for the 'busy (iostat): last 10s' is between 20-100% and typically about 40%.
The napp-it VM has 93 filesystems across 3 pools: 3x NVMe vmdk Z1 / 6x 8TB HDD RAID10 / 8x 3TB HDD Z2, 2x vmxnet3
Memory 48Gb, CPU is Xeon E-2278G 8-core, base 3.4Ghz, boost 5Ghz
What is it processing? is this typical for OmniOS?
Under menu Extensions > Realtime Monitor > should I see some activity?
Edit: It appears to be mostly the interface, as it eventually dropped to 10-15%, a short while after I logged off from from napp-it webgui.
I left napp-it running (logged off) while I was away and then logged back on about 10mins ago, as the ESXi screen grab below.
So for my system, 1x vCPU usage is 10-15% when idle and logged off, and up to 45% when logged on.
BBQ quote "If you're looking, you ain't cooking"
Last edited:
What is it processing? is this typical for OmniOS?
Under menu Extensions > Realtime Monitor > should I see some activity?
If you have enabled acceleration (acc) or monitoring (mon) in napp-it (topmenu right of logout) there are running background tasks. Acc tasks read system informations in the background to improve respondability for some time after last menu actions.
Annoying situation just now. 4x2 raid10 of spinners, with 1 ssd as SLOG device. This is running on latest omnios. I meant to plug in another ssd to do hotplug backups, but pulled the slog device by mistake. Plugged it back in, but the pool is stuck:
NAME STATE READ WRITE CKSUM
jbod DEGRADED 0 0 0
mirror-0 ONLINE 0 0 0
c0t5000C500412EE41Fd0 ONLINE 0 0 0
c0t5000C50041BD3E87d0 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
c0t5000C500426C6F73d0 ONLINE 0 0 0
c0t5000C50055E99CDFd0 ONLINE 0 0 0
mirror-2 ONLINE 0 0 0
c0t5000C50055E9A7A3d0 ONLINE 0 0 0
c0t5000C5005621857Bd0 ONLINE 0 0 0
mirror-3 ONLINE 0 0 0
c0t5000C50056ED546Fd0 ONLINE 0 0 0
c0t5000C50057575FE3d0 ONLINE 0 0 0
logs
c5t5000CCA04DB0D739d0 REMOVED 0 0 0
from dmesg:
Feb 1 09:19:57 omnios zfs: [ID 961531 kern.warning] WARNING: Pool 'jbod' has encountered an uncorrectable I/O failure and has been suspended; `zpool clear` will be required before the pool can be written to.
root@omnios:~# zpool clear jbod
But that is hanging as well. I have a raid1 of 2 ssds serving a vsphere datastore so a reboot at this point is inconvenient. This seems like a bug, no?
NAME STATE READ WRITE CKSUM
jbod DEGRADED 0 0 0
mirror-0 ONLINE 0 0 0
c0t5000C500412EE41Fd0 ONLINE 0 0 0
c0t5000C50041BD3E87d0 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
c0t5000C500426C6F73d0 ONLINE 0 0 0
c0t5000C50055E99CDFd0 ONLINE 0 0 0
mirror-2 ONLINE 0 0 0
c0t5000C50055E9A7A3d0 ONLINE 0 0 0
c0t5000C5005621857Bd0 ONLINE 0 0 0
mirror-3 ONLINE 0 0 0
c0t5000C50056ED546Fd0 ONLINE 0 0 0
c0t5000C50057575FE3d0 ONLINE 0 0 0
logs
c5t5000CCA04DB0D739d0 REMOVED 0 0 0
from dmesg:
Feb 1 09:19:57 omnios zfs: [ID 961531 kern.warning] WARNING: Pool 'jbod' has encountered an uncorrectable I/O failure and has been suspended; `zpool clear` will be required before the pool can be written to.
root@omnios:~# zpool clear jbod
But that is hanging as well. I have a raid1 of 2 ssds serving a vsphere datastore so a reboot at this point is inconvenient. This seems like a bug, no?
Ugh ugh ugh. No time to experiment - it isn't just that pool - nothing is working and guests are failing, so time to do a hard reboot. Damn!!! Even though it said jbod was stuck, apparently I/O involving the ssd raid1 (serving vsphere) was also hosed.
If write stalls to a basic vdev (this is what you have as slog), zfs is waiting forever for the io to be finished as otherwise a dataloss of last sync writes happens.
Action: reboot and "replace" slog with same or remove + readd. Maybe a clear is enough then. Last sync writes lost (up to 4GB of last writes).
Only if there are no uncompleted writes, a slog lost simply switches to onpool logging. One of the cases a slog mirror helps.
Action: reboot and "replace" slog with same or remove + readd. Maybe a clear is enough then. Last sync writes lost (up to 4GB of last writes).
Only if there are no uncompleted writes, a slog lost simply switches to onpool logging. One of the cases a slog mirror helps.
Last edited:
I've looked high and low and can't find an answer, hopefully I just missed it. I have 2 stacked switches. My 3 esxi hosts each have enet connections to them, but not using LACP, just failover order (e.g. nic teaming?) Is it possible to do this for my OmniOS storage appliance? Looking at napp-it gui, I can't see how, just creating a LAG, which I don't want to do (I've had to re-install occasionally on an esxi host, and it's a drag getting it reconnected to the 2 switches so I'm back on.) This is purely a belt and suspenders exercise - I don't need LACP...
I do not use but propably you need link aggregation,
https://docs.oracle.com/cd/E36784_01/html/E37516/gmsab.html#scrolltoc
https://docs.oracle.com/cd/E36784_01/html/E37516/gmsab.html#scrolltoc
napp-it is switching from mini_httpd to Apache 2.4
Up to now the webserver below napp-it is mini_httpd. This is an ultra tiny 50kB single binary webserver. With current operating systems https is no longer working due newer OpenSSL demands. As there is only little work on mini_httpd we decided to move to Apache 24 as this is part of the Solaris and OmniOS extra repository with regular bug and security fixes.
Prior an update to napp-it.dev, install Apache on OmniOS (or rerun the wget installer)
pkg install server/apache-24
A first beta with Apache 24 for OmniOS and the new Solaris 11 CBE is current napp-it 22.dev. After an update Apache should work for http on port 81 and https on port 82. On problems or if you have forgotten to install Apache first, restart Apache manually via "/etc/init.d/napp-it start"
The default Apache config files are under /var/web-gui/data/tools/httpd/apache24/. If you want your own config (update save), use /var/web-gui/_my/tools/apache/httpd.conf as config file.
https://napp-it.org/extensions/amp_en.html
mini_httpd can be started on demand: "/etc/init.d/napp-it mini"
gea
Up to now the webserver below napp-it is mini_httpd. This is an ultra tiny 50kB single binary webserver. With current operating systems https is no longer working due newer OpenSSL demands. As there is only little work on mini_httpd we decided to move to Apache 24 as this is part of the Solaris and OmniOS extra repository with regular bug and security fixes.
Prior an update to napp-it.dev, install Apache on OmniOS (or rerun the wget installer)
pkg install server/apache-24
A first beta with Apache 24 for OmniOS and the new Solaris 11 CBE is current napp-it 22.dev. After an update Apache should work for http on port 81 and https on port 82. On problems or if you have forgotten to install Apache first, restart Apache manually via "/etc/init.d/napp-it start"
The default Apache config files are under /var/web-gui/data/tools/httpd/apache24/. If you want your own config (update save), use /var/web-gui/_my/tools/apache/httpd.conf as config file.
https://napp-it.org/extensions/amp_en.html
mini_httpd can be started on demand: "/etc/init.d/napp-it mini"
gea
Last edited:
Your documentation of SOLARIS derivatives (installation & setup) in general & napp-it in particular, is very extensive. I, quite sure others too, have been relying on them for more than a decade. So I hope that you will also create extensive documentation for Apace 2.4 based napp-it, with command examples & expected outputs shown in the documentation.napp-it is switching from mini_httpd to Apache 2.4
.....
gea
Some questions:
- Can we migrate all napp-it settings from earlier version based on mini_httpd to the newer napp-it based on Apace 2.4?
- Can we delete/remove or at least disable mini_httpd when the new napp-it is completely running on Apache 2.4?
- This is because mini_httpd running in the background would use CPU/RAM resources
- mini_httpd running in the background could also end up interfering with Apache 2.4/napp-it
Hi _Gea
Sorry for the late reply. I didn't want to experiment on the production system that has the ZFS pool which holds all our data. Just finished building a new ZFS pool, where all the data from the old pool will be transferred. Before this transfer takes place, as it's safe to do so, I am currently running various tests.
Just to share folder3b-2 as top SMB share, I can't just create it as a ZFS filesystem inside a normal folder 'folder3b'. So 'folder3b' has to be a filesystem & even 'folder3' has to be a filesystem. At this rate I'll end up with 100, or even more filesystems!
Sorry for the late reply. I didn't want to experiment on the production system that has the ZFS pool which holds all our data. Just finished building a new ZFS pool, where all the data from the old pool will be transferred. Before this transfer takes place, as it's safe to do so, I am currently running various tests.
1. Unfortunately OmniOS/SOLARIS, doesn't allow for filesystems to be created within a normal folder, maybe it's a ZFS limitation. So if I have to create all these filesystems, it may be at least a 100, but possibly even more than that!.....
With up to say a dozen of filesysstems I have or see no problem with this. May be different with hundreds of users and the goal to use a filesysten per user. But This is a layout I would not prefer.
Code:
/
├───folder1
├───folder2
└───folder3
├───folder3a
└───folder3b
├───folder3b-1
└───folder3b-22. I haven't tested this yet, but I've heard that Windows messes up snapshots/Previous Versions when you use multiple filesystems, especially if they're nested.As the pool itself is a ZFS filesystem this would be possible if you enable SMB on the root filesystem with only simple folders below. But as I said, this is not "best use case" and you possibly create more problems than this solves. For example you cannot replicate a pool to the top level of another pool and you cannot use or modify different ZFS properties per use case.
Create one or a few filesystem, share them.
pool/
├───Fs1=share 1
-------- folder 1
-------- folder 2
├───Fs2=share 2
-------- folder 1
-------- folder 2
Is indeed the ZFS layout you should use. Keep everything simple, use ZFS as intended.
From a Client view when you connect the server you will see share1 and share2
1.
A ZFS filesystem can only exist below another ZFS filesystem but can be mounted at any point (must be an empty folder, default mountpoint is /pool/filesystem). A pool itself is also a ZFS filesystem. This is no limitation, this is the way ZFS works. Usually you create a ZFS filesystem ex folder3 with as many regular folders below as needed like folder3a not the other way.
You only want ZFS filesystems instead regular folders when you want different ZFS properties or dedicated replications.
2.
On Solarish with the kernelbased SMB server snaps and shares are both a strict property of a ZFS filesystem. This is why snaps=previous versions work out of the box without problems. This is different when you use SAMBA instead where shares are not strictly related to filesystems what means that the snaps can be on different places within shares. You must then really care about settings or previous versions fail.
A ZFS filesystem can only exist below another ZFS filesystem but can be mounted at any point (must be an empty folder, default mountpoint is /pool/filesystem). A pool itself is also a ZFS filesystem. This is no limitation, this is the way ZFS works. Usually you create a ZFS filesystem ex folder3 with as many regular folders below as needed like folder3a not the other way.
You only want ZFS filesystems instead regular folders when you want different ZFS properties or dedicated replications.
2.
On Solarish with the kernelbased SMB server snaps and shares are both a strict property of a ZFS filesystem. This is why snaps=previous versions work out of the box without problems. This is different when you use SAMBA instead where shares are not strictly related to filesystems what means that the snaps can be on different places within shares. You must then really care about settings or previous versions fail.
22.dev with Apache is a beta, grouping, clustering or remote repication not working!
To downgrade, download 21.06 , 22.01, 22.02 or 22.03 (use mini_httpd)
optionally stop Apache manually via pkill -f bin/httpd
and restart mini_httpd via /etc/init.d/napp-it restart
To downgrade, download 21.06 , 22.01, 22.02 or 22.03 (use mini_httpd)
optionally stop Apache manually via pkill -f bin/httpd
and restart mini_httpd via /etc/init.d/napp-it restart
Hi all
I’ve recently tried a fresh install of OI + napp-it on an HP Microserver (NL-36) and get the following message (error?) when going to either the “Pools or “ZFS Filesystems” menu:
Can't load '/var/web-gui/data/napp-it/CGI/auto/IO/Tty/Tty.so' for module IO::Tty: ld.so.1: perl: fatal: libgcc_s.so.1: open failed: No such file or directory at /usr/perl5/5.22/lib/i86pc-solaris-64int/DynaLoader.pm line 193. at /var/web-gui/data/napp-it/CGI/IO/Tty.pm line 30. Compilation failed in require at /var/web-gui/data/napp-it/CGI/IO/Pty.pm line 7. BEGIN failed--compilation aborted at /var/web-gui/data/napp-it/CGI/IO/Pty.pm line 7. Compilation failed in require at /var/web-gui/data/napp-it/CGI/Expect.pm line 23. BEGIN failed--compilation aborted at /var/web-gui/data/napp-it/CGI/Expect.pm line 23. Compilation failed in require at /var/web-gui/data/napp-it/zfsos/_lib/illumos/zfslib.pl line 2890. BEGIN failed--compilation aborted at /var/web-gui/data/napp-it/zfsos/_lib/illumos/zfslib.pl line 2890. Compilation failed in require at admin.pl line 419.
I’ve tried fresh installs using various combinations of:
I’ve also tried re-running the online wget installer and also the command "ln -s /usr/gcc/6/lib/libgcc_s.so.1 /usr/lib/libgcc_s.so.1" as detailed on the OpenIndiana page on the napp-it website. Unfortunately still get the same message.
The server was previously running older versions of OI and napp-it from around 2013. I’ve got another HP Microserver running OI 20.10 with napp-it 18.12w7 that is working as expected.
Any ideas how to resolve this as I can’t create a storage pool using napp-it.
Thanks
I’ve recently tried a fresh install of OI + napp-it on an HP Microserver (NL-36) and get the following message (error?) when going to either the “Pools or “ZFS Filesystems” menu:
Can't load '/var/web-gui/data/napp-it/CGI/auto/IO/Tty/Tty.so' for module IO::Tty: ld.so.1: perl: fatal: libgcc_s.so.1: open failed: No such file or directory at /usr/perl5/5.22/lib/i86pc-solaris-64int/DynaLoader.pm line 193. at /var/web-gui/data/napp-it/CGI/IO/Tty.pm line 30. Compilation failed in require at /var/web-gui/data/napp-it/CGI/IO/Pty.pm line 7. BEGIN failed--compilation aborted at /var/web-gui/data/napp-it/CGI/IO/Pty.pm line 7. Compilation failed in require at /var/web-gui/data/napp-it/CGI/Expect.pm line 23. BEGIN failed--compilation aborted at /var/web-gui/data/napp-it/CGI/Expect.pm line 23. Compilation failed in require at /var/web-gui/data/napp-it/zfsos/_lib/illumos/zfslib.pl line 2890. BEGIN failed--compilation aborted at /var/web-gui/data/napp-it/zfsos/_lib/illumos/zfslib.pl line 2890. Compilation failed in require at admin.pl line 419.
I’ve tried fresh installs using various combinations of:
- OpenIndiana Hipster 21.10, 21.04 and 20.10
- napp-it 21.06a7 and 18.12w9 (using the downgrade option)
I’ve also tried re-running the online wget installer and also the command "ln -s /usr/gcc/6/lib/libgcc_s.so.1 /usr/lib/libgcc_s.so.1" as detailed on the OpenIndiana page on the napp-it website. Unfortunately still get the same message.
The server was previously running older versions of OI and napp-it from around 2013. I’ve got another HP Microserver running OI 20.10 with napp-it 18.12w7 that is working as expected.
Any ideas how to resolve this as I can’t create a storage pool using napp-it.
Thanks
The Tty.so is part of Expect. This error results from a newer unsupported Perl.
Part of napp-it is Tty.so from OmniOS for Perl up to 5.34. It worked for OI as well.
Does the problem remains after a logout/login in napp-it?
What is the output of perl -v
btw
OI is more critical than OmniOS as there are sudden changes in OI as it always use ongoing Illumos.
OmniOS in contrast has a dedicated repository per stable release with no newer features but only security and bugfixes up to next stable what avoids sudden updates and makes it much more suitable for a reliable storage server.
Part of napp-it is Tty.so from OmniOS for Perl up to 5.34. It worked for OI as well.
Does the problem remains after a logout/login in napp-it?
What is the output of perl -v
btw
OI is more critical than OmniOS as there are sudden changes in OI as it always use ongoing Illumos.
OmniOS in contrast has a dedicated repository per stable release with no newer features but only security and bugfixes up to next stable what avoids sudden updates and makes it much more suitable for a reliable storage server.
Thanks _Gea for the quick reply.Does the problem remains after a logout/login in napp-it?
What is the output of perl -v
Problem still remains after logout/login in napp-it and also after restarting the gui.
Output of perl -v
- “perl 5, version 22, subversion 4 (v5.22.4)”
My other Microserver (which works fine) is also running perl v5.22.4. It is running napp-it v18.12w7 (free)
Based on your comments, I’ll try OmniOS (esp now that it has a dialogue based installer)
Thanks
OmniOS 151042 stable is out,
https://github.com/omniosorg/omnios-build/blob/r151042/doc/ReleaseNotes.md
Release 151030 LTS is now end-of-life.
You should upgrade to r151038 to stay on a supported LTS track.
btw
OmniOS is fully Open Source and free.
Nevertheless, it takes a lot of time and money to keep maintaining a full-blown operating system distribution.
If you use OmniOS, consider a support contract, Commercial Support
or becoming a patron, Donate
https://github.com/omniosorg/omnios-build/blob/r151042/doc/ReleaseNotes.md
Release 151030 LTS is now end-of-life.
You should upgrade to r151038 to stay on a supported LTS track.
btw
OmniOS is fully Open Source and free.
Nevertheless, it takes a lot of time and money to keep maintaining a full-blown operating system distribution.
If you use OmniOS, consider a support contract, Commercial Support
or becoming a patron, Donate
Either via ntpdate (default up to 151038) or chrony (default now) and an "other job",
https://illumos.topicbox.com/groups/omnios-discuss/T5fc9cf2343c39195/fresh-install-vs-upgrade
https://illumos.topicbox.com/groups/omnios-discuss/T5fc9cf2343c39195/fresh-install-vs-upgrade
when i run ntpdate, i got this:Either via ntpdate (default up to 151038) or chrony (default now) and an "other job",
https://illumos.topicbox.com/groups/omnios-discuss/T5fc9cf2343c39195/fresh-install-vs-upgrade
root@omni:~# ntpdate
ntpdig: no eligible servers

OmniOS update
In the meantime we are at 151042o
https://github.com/omniosorg/omnios-build/blob/r151042/doc/ReleaseNotes.md
among others
- Fix for a rare kernel panic due to a race condition in poll()
- AMD CPU microcode updated to latest versions as of 20220408
- OpenSSL updated to version 1.1.1q and 3.0.5
- Updates to ZFS to gracefully handle unknown/invalid vdev device IDs
In the meantime we are at 151042o
https://github.com/omniosorg/omnios-build/blob/r151042/doc/ReleaseNotes.md
among others
- Fix for a rare kernel panic due to a race condition in poll()
- AMD CPU microcode updated to latest versions as of 20220408
- OpenSSL updated to version 1.1.1q and 3.0.5
- Updates to ZFS to gracefully handle unknown/invalid vdev device IDs
NVMe Pools can make problems on OS downgrades
https://illumos.topicbox.com/groups/discuss/T4033e3489b51199d/heads-up-zfs-on-nvme-after-14686
https://www.illumos.org/issues/14686
"If you're not using ZFS on NVMe devices, you can ignore this message.
With the integration of #14686, the nvme driver will start to use new
devid types specifically created for NVMe. Updating to #14686 will be
handled gracefully by ZFS, old pools will import correctly and will have
their vdev labels updated with the new devid types automatically.
After updating to #14686, older illumos versions may fail to import the
ZFS pools as they may get confused by the new (unknown) devid types. To
handle this, #14745 has been integrated in illumos on June 24th,
allowing ZFS to import pools on vdevs with unknown or invalid devids.
In order to be able to import your ZFS pools on an older illumos version
before #14686, such as when booting any earlier boot environment from
before #14686, you must use an illumos version that already has #14745
but not yet #14686, resetting the devids to the older types when
importing the pools. After that you can go back even further before
#14745.
The illumos distribution maintainers have been informed about this issue
and should have backported #14745 to any releases they support. Please
consult your distributions release notes for more information."
https://illumos.topicbox.com/groups/discuss/T4033e3489b51199d/heads-up-zfs-on-nvme-after-14686
https://www.illumos.org/issues/14686
"If you're not using ZFS on NVMe devices, you can ignore this message.
With the integration of #14686, the nvme driver will start to use new
devid types specifically created for NVMe. Updating to #14686 will be
handled gracefully by ZFS, old pools will import correctly and will have
their vdev labels updated with the new devid types automatically.
After updating to #14686, older illumos versions may fail to import the
ZFS pools as they may get confused by the new (unknown) devid types. To
handle this, #14745 has been integrated in illumos on June 24th,
allowing ZFS to import pools on vdevs with unknown or invalid devids.
In order to be able to import your ZFS pools on an older illumos version
before #14686, such as when booting any earlier boot environment from
before #14686, you must use an illumos version that already has #14745
but not yet #14686, resetting the devids to the older types when
importing the pools. After that you can go back even further before
#14745.
The illumos distribution maintainers have been informed about this issue
and should have backported #14745 to any releases they support. Please
consult your distributions release notes for more information."
Last edited:
So I set up 3 zvols shared via comstar. I then backed up the comstar config file and move it off the root disk. I was messing around and decided to restore the config. The pull down menu for this doesn't seem to accept a file to restore (e.g. it's got some file hardcoded with the current date, so even if I hadn't moved the config off /var, it wouldn't restore it unless I renamed it? Am I missing something? Also, does comstar log any kind of information to facilitate diagnosing issues. I have an iSCSI enet card that doesn't seem to see the storage, yet I can see it fine from windows 10 (I even deleted the restrictive view and set one as all/all and that didn't help.) Running tcpdump, I can see packets going back and forth, but that isn't at all helpful.
Last edited:
There are two options to save/restore Comstar iSCSI settings in napp-it
1. very basic service settings in menu Comstar > Basic Save/Restore
https://docs.oracle.com/cd/E26502_01/html/E29006/fnnop.html#glecq
This creates an XML service textfile /var/web-gui/_log/'date'.bkp that can be used for a restore.
2. Complete settings (LUs, views, targets, target groups and target portal groups)
in menu Comstar > Full HA save/restore.
When you create a full backup of your settings, you must select a pool (ex rpool, tank or a HA pool).
Result of the backup function is a shellscript in /var/web-gui/_log/iscsi/restore.sh or
"pool"/backup_appliance/web-gui/_log/iscsi/restore.sh (+ older backup versions).
A restore starts this script for a full restore (re-creation) of all Comstar settings,
either for a regular restore or for a restore after a HA failover
1. very basic service settings in menu Comstar > Basic Save/Restore
https://docs.oracle.com/cd/E26502_01/html/E29006/fnnop.html#glecq
This creates an XML service textfile /var/web-gui/_log/'date'.bkp that can be used for a restore.
2. Complete settings (LUs, views, targets, target groups and target portal groups)
in menu Comstar > Full HA save/restore.
When you create a full backup of your settings, you must select a pool (ex rpool, tank or a HA pool).
Result of the backup function is a shellscript in /var/web-gui/_log/iscsi/restore.sh or
"pool"/backup_appliance/web-gui/_log/iscsi/restore.sh (+ older backup versions).
A restore starts this script for a full restore (re-creation) of all Comstar settings,
either for a regular restore or for a restore after a HA failover
Sorry,
I have not connected a target directly from a nic.
Ok, but that wasn't really my point. Whether it's a NIC, an HBA or a SW initiator, I would like to be able to debug on the omnios end, by seeing what comstar is doing.
Unless there is no Comstar error or fault situation that initiates a syslog of fault entry, I suppose you can only log network traffic and compare with a different working target.
For more debugging options you may ask at Illumos dev maillist.
For more debugging options you may ask at Illumos dev maillist.
Gea,
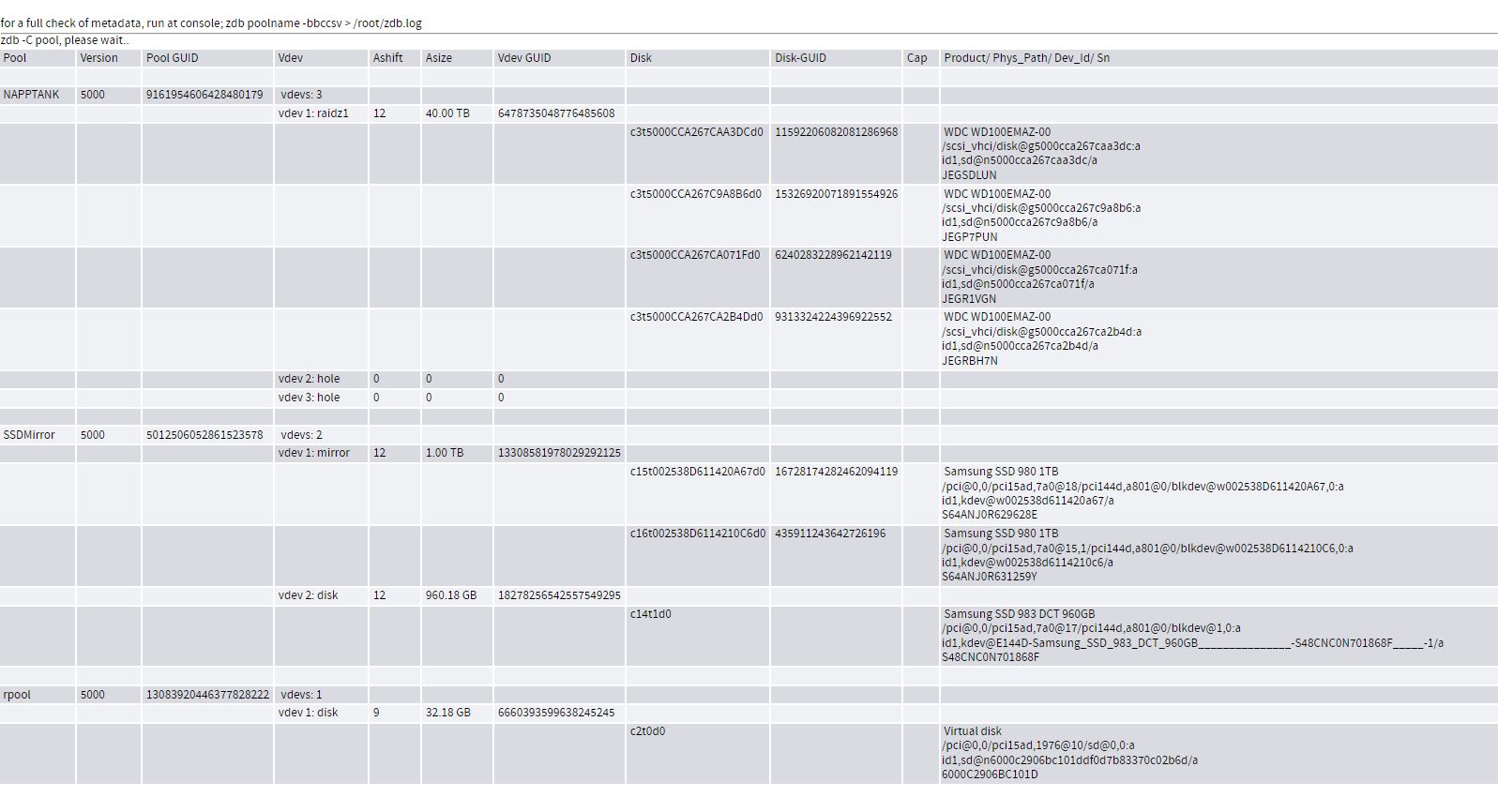
I've got a pool that was created back in 2014 and I've swapped out drives over the years to grow my pool, now running four 10TB 4K drives. I noticed when I looked at my RAIDZ1 pool 'NAPPTANK' with the four 10TB drives that the 'ashift' value is 0. I've read that this cannot be changed after the pool has been created.
is 'ashift=0' and auto detect?
I've included some of my existing 10TB drive info below.
Whats the best course of action one could take to correct this?
Thanks!
EDIT: after looking at the ZDB details, it reports that the pool NAPPTANK is 'ashift=12' after all. Should I modify SD.CONF and set 'ashift=12' in there? It was confusing reading just the 'NAPPTANK' pool properties that initially reports 'ashift=0'.
I've got a pool that was created back in 2014 and I've swapped out drives over the years to grow my pool, now running four 10TB 4K drives. I noticed when I looked at my RAIDZ1 pool 'NAPPTANK' with the four 10TB drives that the 'ashift' value is 0. I've read that this cannot be changed after the pool has been created.
is 'ashift=0' and auto detect?
I've included some of my existing 10TB drive info below.
Whats the best course of action one could take to correct this?
Thanks!
un_phy_blocksize = 0x1000 (4k) | WDC WD100EMAZ-00
EDIT: after looking at the ZDB details, it reports that the pool NAPPTANK is 'ashift=12' after all. Should I modify SD.CONF and set 'ashift=12' in there? It was confusing reading just the 'NAPPTANK' pool properties that initially reports 'ashift=0'.
Pool details zdb -C NAPPTANK
MOS Configuration:
version: 5000
name: 'NAPPTANK'
state: 0
txg: 49801354
pool_guid: 9161954606428480179
errata: 0
hostid: 659976810
hostname: 'OMNIOS'
com.delphix:has_per_vdev_zaps
hole_array[0]: 1
vdev_children: 3
vdev_tree:
type: 'root'
id: 0
guid: 9161954606428480179
children[0]:
type: 'raidz'
id: 0
guid: 6478735048776485608
nparity: 1
metaslab_array: 30
metaslab_shift: 37
ashift: 12
asize: 40003271917568
is_log: 0
create_txg: 4
com.delphix:vdev_zap_top: 205
children[0]:
type: 'disk'
id: 0
guid: 11592206082081286968
path: '/dev/dsk/c3t5000CCA267CAA3DCd0s0'
devid: 'id1,sd@n5000cca267caa3dc/a'
phys_path: '/scsi_vhci/disk@g5000cca267caa3dc:a'
whole_disk: 1
DTL: 107769
create_txg: 4
com.delphix:vdev_zap_leaf: 3139
children[1]:
type: 'disk'
id: 1
guid: 15326920071891554926
path: '/dev/dsk/c3t5000CCA267C9A8B6d0s0'
devid: 'id1,sd@n5000cca267c9a8b6/a'
phys_path: '/scsi_vhci/disk@g5000cca267c9a8b6:a'
whole_disk: 1
DTL: 107768
create_txg: 4
com.delphix:vdev_zap_leaf: 16438
children[2]:
type: 'disk'
id: 2
guid: 6240283228962142119
path: '/dev/dsk/c3t5000CCA267CA071Fd0s0'
devid: 'id1,sd@n5000cca267ca071f/a'
phys_path: '/scsi_vhci/disk@g5000cca267ca071f:a'
whole_disk: 1
DTL: 107767
create_txg: 4
com.delphix:vdev_zap_leaf: 614
children[3]:
type: 'disk'
id: 3
guid: 9313324224396922552
path: '/dev/dsk/c3t5000CCA267CA2B4Dd0s0'
devid: 'id1,sd@n5000cca267ca2b4d/a'
phys_path: '/scsi_vhci/disk@g5000cca267ca2b4d:a'
whole_disk: 1
DTL: 107766
create_txg: 4
com.delphix:vdev_zap_leaf: 31369
children[1]:
type: 'hole'
id: 1
guid: 0
whole_disk: 0
metaslab_array: 0
metaslab_shift: 0
ashift: 0
asize: 0
is_log: 0
is_hole: 1
children[2]:
type: 'disk'
id: 2
guid: 10251713868127739504
path: '/dev/dsk/c14t1d0s0'
devid: 'id1,kdev@E144D-Samsung_SSD_983_DCT_960GB_______________-S48CNC0N701868F_____-1/a'
phys_path: '/pci@0,0/pci15ad,7a0@17/pci144d,a801@0/blkdev@1,0:a'
whole_disk: 1
metaslab_array: 170
metaslab_shift: 33
ashift: 9
asize: 960183664640
is_log: 1
DTL: 107765
create_txg: 42685425
com.delphix:vdev_zap_leaf: 108
com.delphix:vdev_zap_top: 129
features_for_read:
com.delphix:hole_birth
com.delphix:embedded_data
Last edited:
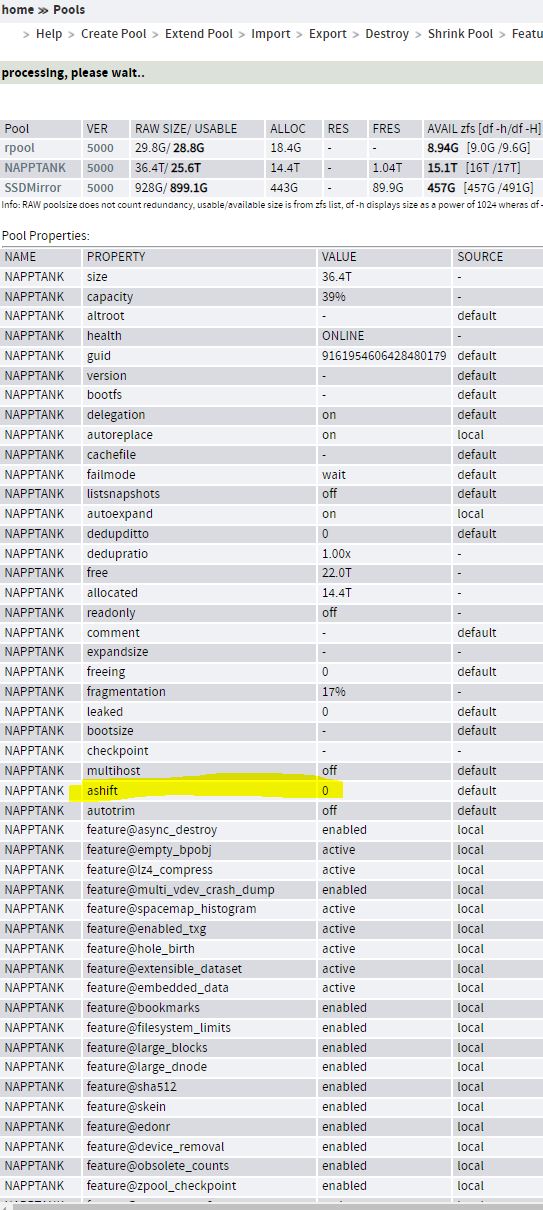
1. can you add output of menu Pools with vdev structure and disk manufacturer and
menu Pools > Poolinfo with ashift values. (best a screenshot).
In general:
- Ashift is not a pool property but a vdev property
- sd.conf is no longer the method to set ashift. You can force ashift during vdev creation
- ashift can only be set during creation, not afterwards. If ashift is different on vdevs you can only fix with a new pool
- some disk remove operations ex special vdevs require all vdevs with same ashift
- disk replace with vdevs and ashift=9 and disks with physical 4k (ashift=12) fails
- ashift=0 ??. Have not had that, so post infos from 1.
menu Pools > Poolinfo with ashift values. (best a screenshot).
In general:
- Ashift is not a pool property but a vdev property
- sd.conf is no longer the method to set ashift. You can force ashift during vdev creation
- ashift can only be set during creation, not afterwards. If ashift is different on vdevs you can only fix with a new pool
- some disk remove operations ex special vdevs require all vdevs with same ashift
- disk replace with vdevs and ashift=9 and disks with physical 4k (ashift=12) fails
- ashift=0 ??. Have not had that, so post infos from 1.
Last edited:
NAPP-IT v22.03b
Gea,
Pool info & properties have been attached.
I see 'ashift 0' after I click on my NAPPTANK pool hyperlink after I click on the menu 'Pools' and it displays the properties. Its prolly not an issue as it reports '12' in other areas.
Hardware:
1GB Network - shopping for 10GBE
Dell R720 w/128GB RAM - 2CPUs Xeon CPU E5-2640 @ 2.5GHz (six cores)
ESXi installed on a SSD - boot drive
NAPP-IT is a VM on its own SSD and sharing the SSDMirror pool over NFS to ESXi, so the VMs do not appear in ESXi until NAPP-IT is up and running.
NAPPTANK is my main pool with all of my data for the NAS
SSDMirror is a pair of mirrired SSDs that contains my VMs
I'm having very poor file copy performance when I copy files that live in my NAPPTANK pool to a VM that exists in the SSDMirror pool, while I can move large files no problem. I currently only have one NIC connected to the Dell R720 for all connections. I should probably look into doing a passthru for NICs to certain VMs. What benchmark test is the best one to run to demonstrate this?
Thank you
Gea,
Pool info & properties have been attached.
I see 'ashift 0' after I click on my NAPPTANK pool hyperlink after I click on the menu 'Pools' and it displays the properties. Its prolly not an issue as it reports '12' in other areas.
Hardware:
1GB Network - shopping for 10GBE
Dell R720 w/128GB RAM - 2CPUs Xeon CPU E5-2640 @ 2.5GHz (six cores)
ESXi installed on a SSD - boot drive
NAPP-IT is a VM on its own SSD and sharing the SSDMirror pool over NFS to ESXi, so the VMs do not appear in ESXi until NAPP-IT is up and running.
NAPPTANK is my main pool with all of my data for the NAS
SSDMirror is a pair of mirrired SSDs that contains my VMs
I'm having very poor file copy performance when I copy files that live in my NAPPTANK pool to a VM that exists in the SSDMirror pool, while I can move large files no problem. I currently only have one NIC connected to the Dell R720 for all connections. I should probably look into doing a passthru for NICs to certain VMs. What benchmark test is the best one to run to demonstrate this?
Thank you
Attachments

Last edited: