Does not really matter
- you can update OmniOS + napp-it independently
- you can use a newer VM template (with a newer OmniOS and napp-it)
You may need to redo user settings or napp-it settings
- Export > Import a pool is the proper way
But you can import a pool without a prior export - no problem
- you can update OmniOS + napp-it independently
- you can use a newer VM template (with a newer OmniOS and napp-it)
You may need to redo user settings or napp-it settings
- Export > Import a pool is the proper way
But you can import a pool without a prior export - no problem
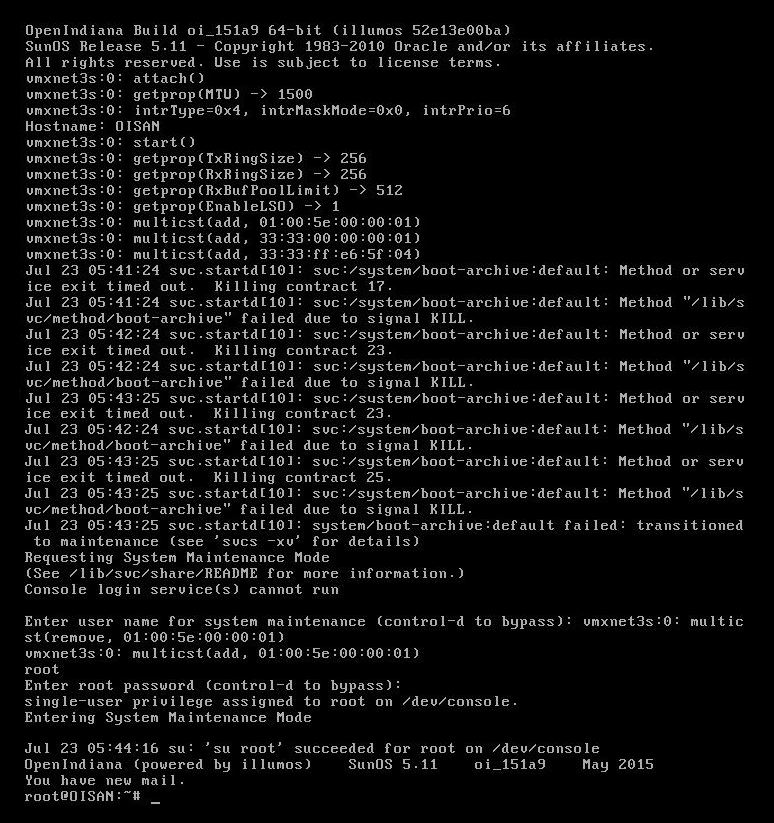
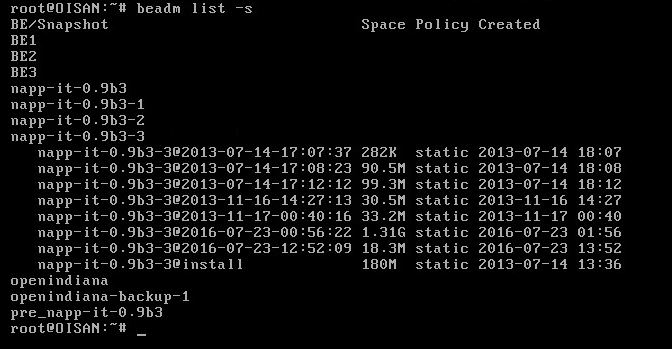
 roduct-id=VMware-Virtual-Platform:server-id=OISAN:chassis-id=VMware-56-4d-b8-11-bf-0c-1b-a4-85-a0-da-c3-67-e6-5f-04/motherboard=0)
roduct-id=VMware-Virtual-Platform:server-id=OISAN:chassis-id=VMware-56-4d-b8-11-bf-0c-1b-a4-85-a0-da-c3-67-e6-5f-04/motherboard=0)