does this particular smb3 implementation work with hyper-v? i mean as vm storage of course
I have only read the announcement.
You may ask at Nexenta.com forums.
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
does this particular smb3 implementation work with hyper-v? i mean as vm storage of course
Expect.pm is a CPAN Perl module.
You may try to install Expect again afterwards.
Other option may be using Joyent pkin modules instead
as they install everything in /opt reducing dependencies with core OS settings.
see http://napp-it.org/downloads/binaries.html
http://pkgsrc.joyent.com/packages/SmartOS/2014Q4/x86_64/All/
Last option is a VM or zone
<username>@Plex:/var/lib/plexmediaserver/Library/Application Support$ ls -l
total 9
drwxrwxrwx 10 messagebus users 11 Mar 25 12:32 Plex Media Server
The above setting creates 48 snaps per day.
As keep and hold are respected both, hold 3 days is the effective setting
what means that you should have 144 snaps
If snap is recursive, you have 144 snaps x number of filesystems.
We have 2 of these cases:
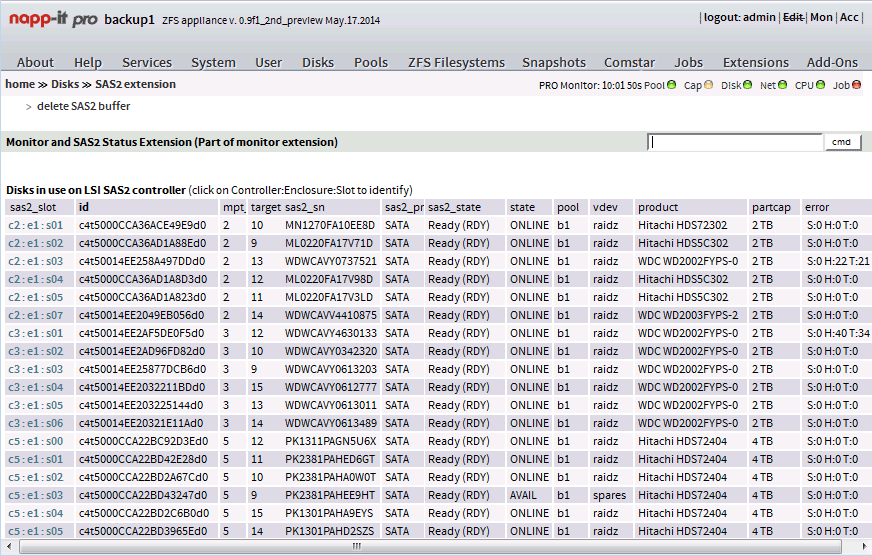
http://www.supermicro.com/products/chassis/3U/837/SC837E26-RJBOD1.cfm
This is occuring on only one machine, but then again, we only have one storage server with OmniOS and setup like that.
Matej
Backplane
- BPN-SAS2-837EL2 +
- BPN-SAS-837A
Hmmmm. Are you using both ports, just one? Sata or SAS drives or mix?
1. Which disks make/manufacturer?
2. Are you passing the disks to ZFS for management or using hardware raid and passing the array through or?
Current active firmware version is 0f000000 (15.00.00)
Firmware image's version is MPTFW-15.00.00.00-IT
LSI Logic
Not Packaged Yet
x86 BIOS image's version is MPT2BIOS-7.29.00.00 (2012.11.12)
EFI BIOS image's version is 7.22.01.00
How do I find out which device/drive is the one causing me problems?Apr 2 09:23:15 storage.host.org scsi: [ID 107833 kern.notice] /pci@0,0/pci8086,3c02@1/pci1000,3040@0 (mpt_sas0):
Apr 2 09:23:15 storage.host.org Timeout of 0 seconds expired with 1 commands on target 68 lun 0.
Apr 2 09:23:15 storage.host.org scsi: [ID 107833 kern.warning] WARNING: /pci@0,0/pci8086,3c02@1/pci1000,3040@0 (mpt_sas0):
Apr 2 09:23:15 storage.host.org Disconnected command timeout for target 68 w500304800039d83d, enclosure 3
Apr 2 09:23:15 storage.host.org scsi: [ID 365881 kern.info] /pci@0,0/pci8086,3c02@1/pci1000,3040@0 (mpt_sas0):
Apr 2 09:23:15 storage.host.org Log info 0x31140000 received for target 68 w500304800039d83d.
Apr 2 09:23:15 storage.host.org scsi_status=0x0, ioc_status=0x8048, scsi_state=0xc
1 Raw_Read_Error_Rate 0x000f 068 063 044 Pre-fail Always - 6424418
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
7 Seek_Error_Rate 0x000f 092 060 030 Pre-fail Always - 1773170504
195 Hardware_ECC_Recovered 0x001a 062 003 000 Old_age Always - 6424418
Also, new drives will be all SAS, but 3 years ago, when we bought the current JBODs, SAS drives were still very expensive...1.
once started it will run
2.
replication extension, options see
http://napp-it.org/extensions/quotation_en.html
3.
enter the ip of the source server with its napp-it admin pw (not root pw)
some char are not allowed in your password, optionally try a pw from [A-Za-z0-9]
Most probably
- you have additional snaps on source
the replication parameter -I includes them otherwise only the basic and last are used (default)
- replication decodes compress or dedup,
if source is not compressed but target (parent) is, then this can be the result
- suboptimal ZFS layout on source, example nonoptimal amount of 4k disks in a raid-Z
(would not give a 30% difference but can increase other effects)