Anarchist4000
[H]ard|Gawd
- Joined
- Jun 10, 2001
- Messages
- 1,659
The queues won't be sending single instructions, they'll be doing blocks if not the entire program into a warp/wave. A SMM should just need 1 copy of the kernel/program to share among all similar warps/waves to track progress. It might page in/out portions of the program if it's big, but it's only instructions that should be relatively small. A queue is probably going to dispatch all of it's work before going on to the 2nd queue. It's possible they get multiplexed, but each queue would definitely be a different block and kernel. Yes they could technically be the same, but the scheduler won't know that. With Nvidia they will dispatch all(up to) 32 queues and let them run to completion before getting more work from the CPU.



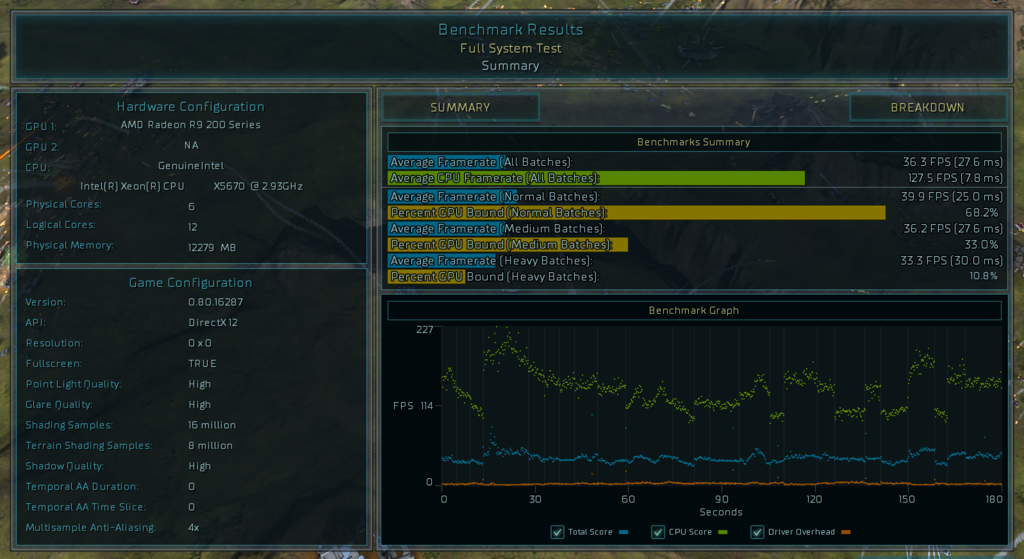

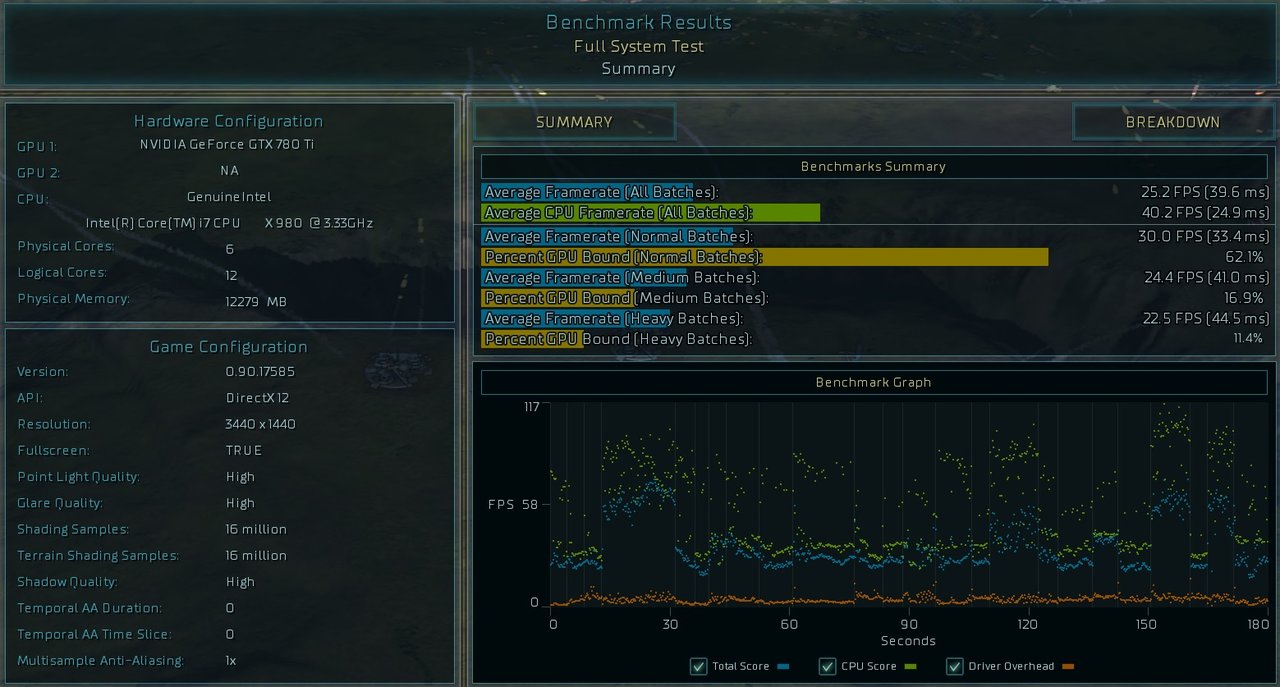
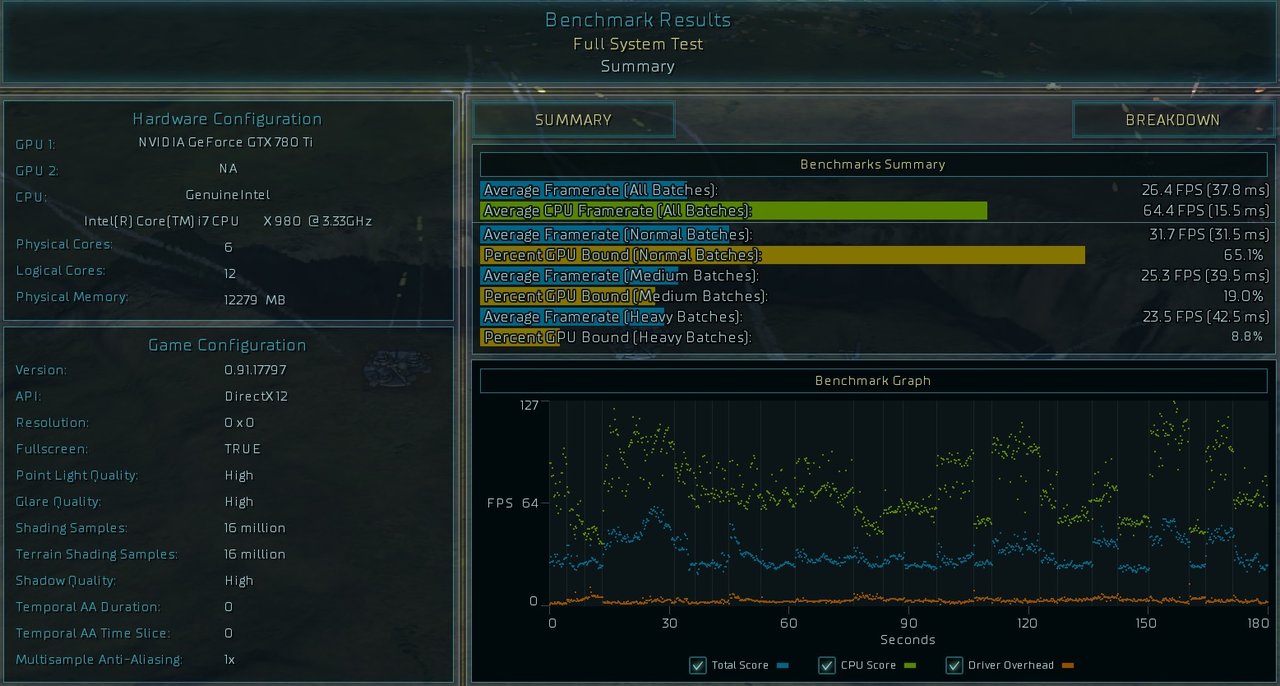






") Game really pushes the hardware.
Game really pushes the hardware.