Navigation
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
More options
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
OpenSolaris derived ZFS NAS/ SAN (OmniOS, OpenIndiana, Solaris and napp-it)
- Thread starter _Gea
- Start date
Gea, and anyone else who would care to answer:
I'm building a ZFS server, trying to make it as fast, quiet and cool as possible. I'm experimenting with 8 Crucial m500 960GB SSDs that I borrowed temporarily from work.
My main question regards TRIM support for these drives. Correct me if I'm wrong, but I don't believe any of the Illumos/Solaris OSs have TRIM support. My main question is, should I be concerned about this? In other words, will performance substantially drop off over time? My usage pattern will be primarily read-heavy, which I think would help. Although, the plan is to periodically dump older stuff off the SSD pool onto a much larger HDD pool, so I suppose the space on the SSD array will get habitually reused.
FreeBSD 10.0 (and possibly 9.2) does offer TRIM support for SSDs in a ZFS pool. My first experiment was (and is) with that, and so far so good. But I've always used Illumos in the past and I wonder if that is an option in this case.
By the way, doing a simple local dd if=/dev/zero test to the array as described in this post is yielding over 2GB/sec, which I was pretty impressed with. The NIC is an Intel 10GbE (x540-T1), BTW, but I have not tested throughput over the network yet (working on configuring Samba at this point).
Semi-unrelated but open for comments: What is the general consensus regarding running those 8 SSDs in a single-parity (RAIDZ1) config? My thoughts were that they are relatively small drives, reading is not hard on SSDs, and SSDs have a high MTBF so the risk of RAIDZ1 seemed low, and therefore I opted to get an additional 960GB of usable space vs the additional protection of RAIDZ2. Does that seem like a good choice in this case? I wouldn't do it with 4TB HDDs, but for 1TB SSDs it seemed reasonable to me.
Thanks to all.
Seems like either my question got overlooked or nobody has anything to add. In any case, since posting I've become somewhat more educated about write consistency in SSDs, even in the absence of TRIM. It seems that doing a decent amount of overprovisioning should help dramatically with keeping write performance consistent. This allows me to run on an Illumos OS (OmniOS) which was what I really wanted (instead of FreeBSD, which now has TRIM for ZFS, which I thought I needed).
I have ordered eight Samsung 840 1TB drives. Samsung has a utility that allows the user to set the overprovisioning amount. I plan to set to around 20%. I hate to give up all that space but what good are SSDs if their performance falls off a cliff?
The point of the updated post is simply to see if anyone has any comments about making a RAIDZ1 pool of eight Samsung 840 1TB drives overprovisioned down to 800GB each. Specifically:
- Has anyone used these drives for ZFS pools?
- Does my choice of RAIDZ1 in this case seem foolish or reasonable?
- Any comments on the write consistency / overprovisioning issue?
Thanks.
Gea,
Replication progress percentage works during the initial seed, however incremental replications just say "running % n.a." for hours with no way to monitor progress. I am running v0.9d2 nightly on all of my boxes, just wondering if you had a quick fix to see percentage?
This wasn't an issue on-site, however now we are replicating over (relatively) slow WAN at 2 MB/s and its becoming an issue.
I have the replication jobs scheduled to run nightly, but am unsure how napp-it auto service will handle the scheduled replication job if it is still running during the next scheduled time. I would hate to have to re-seed my 6TB pool!
Thanks again for all your help!
Replication progress percentage works during the initial seed, however incremental replications just say "running % n.a." for hours with no way to monitor progress. I am running v0.9d2 nightly on all of my boxes, just wondering if you had a quick fix to see percentage?
This wasn't an issue on-site, however now we are replicating over (relatively) slow WAN at 2 MB/s and its becoming an issue.
I have the replication jobs scheduled to run nightly, but am unsure how napp-it auto service will handle the scheduled replication job if it is still running during the next scheduled time. I would hate to have to re-seed my 6TB pool!
Thanks again for all your help!
Seems like either my question got overlooked or nobody has anything to add. In any case, since posting I've become somewhat more educated about write consistency in SSDs, even in the absence of TRIM. It seems that doing a decent amount of overprovisioning should help dramatically with keeping write performance consistent. This allows me to run on an Illumos OS (OmniOS) which was what I really wanted (instead of FreeBSD, which now has TRIM for ZFS, which I thought I needed).
I have ordered eight Samsung 840 1TB drives. Samsung has a utility that allows the user to set the overprovisioning amount. I plan to set to around 20%. I hate to give up all that space but what good are SSDs if their performance falls off a cliff?
The point of the updated post is simply to see if anyone has any comments about making a RAIDZ1 pool of eight Samsung 840 1TB drives overprovisioned down to 800GB each. Specifically:
- Has anyone used these drives for ZFS pools?
- Does my choice of RAIDZ1 in this case seem foolish or reasonable?
- Any comments on the write consistency / overprovisioning issue?
Thanks.
1. not me
2. regarding performance and I/O, raid z1 is ok
I prefer Raid-Z2 as the failure rate of SSDs is similar to disks. The rebuild time is very fast if you have a spare. But in such a case, you can use Z2 as well (more expensive)
3. If the OS does not support Trim on Raid, you can use either modern SSDs with advanced build in logic, you can overprovision or do not fill the SSD up to the end.
Gea,
Replication progress percentage works during the initial seed, however incremental replications just say "running % n.a." for hours with no way to monitor progress. I am running v0.9d2 nightly on all of my boxes, just wondering if you had a quick fix to see percentage?
This wasn't an issue on-site, however now we are replicating over (relatively) slow WAN at 2 MB/s and its becoming an issue.
I have the replication jobs scheduled to run nightly, but am unsure how napp-it auto service will handle the scheduled replication job if it is still running during the next scheduled time. I would hate to have to re-seed my 6TB pool!
Thanks again for all your help!
ZFS send/receive does not offer progress informations. For the initial transfer I compare the size of the source filesystem vs the target one. For incremental transfers there is no similar workaround. But mostly not a problem as they are finished quite quickly.
1. not me
2. regarding performance and I/O, raid z1 is ok
I prefer Raid-Z2 as the failure rate of SSDs is similar to disks. The rebuild time is very fast if you have a spare. But in such a case, you can use Z2 as well (more expensive)
3. If the OS does not support Trim on Raid, you can use either modern SSDs with advanced build in logic, you can overprovision or do not fill the SSD up to the end.
Gea, thanks. My logic for going Z1 was:
1. SSDs have a limited write lifetime but I don't think this is true of reads. To resilver a failed SSD to a new one should only require reads for the other ones, so it doesn't seem that this would "stress" them in the same way a pool of HDDs would be stressed during a resilver.
2. The SSDs are reasonably small, so the amount of data accessed from each one should be small and the resilver should therefore not take much time. Again, it seems that this would reduce the failure rate in the other drives due to resilvering.
This is in contrast to a pool of say, 4TB HDDs where a resilver would cause each drive to read a LOT of data, and in HDDs, reads are just as stressful to the drive as writes.
Does my logic make sense?
In any case I may just spend the bucks and do a pool of 16 drives. If I do that, I will certainly go for Z2 if for no other reason than I will have more space overhead.
One more question. If the Samsungs I ordered work out, I can overprovision them using a Samsung utility and the drives will simply report a lower capacity to the OS. If however I end up using different SSDs, from a manufacturer which does not provide such a nice utility, I will be left to (1) make sure the SSDs are in virgin state via a secure erase and (2) partition the drives so that a portion of their capacity is never used.
If I end up having to partition the drives, what would be the steps on Illumos-based OSs to accomplish this? What I mean is, what command sequence would I use to create the partitions and then how would my zpool create look?
Thanks.
Don't remember the exact command sequence, but the gist is: use format command then using the fdisk subcommand create a solaris2 using 100% of the disk. save using option 6 and then do the 'partition' subcommand to create a slice zero using say 90% of the top-level partition. Then 'zpool add tank cXtYdZs0.
Gea,
somehow my replication is already screwed up its first week offsite. The job failed (and didn't alert me via email) with error:
info: 554: incremental zfs receive error after 5 s cannot receive incremental stream: most recent snapshot of pool01-das01/datastore08 does not match incremental source
src snaps: pool01-esx/datastore08@1391145061_repli_zfs_omni-san05_nr_13 -> pool01-esx/datastore08@1391145061_repli_zfs_omni-san05_nr_14
dest: pool01-das01/datastore08 with last snap pool01-esx/datastore08@1391145061_repli_zfs_omni-san05_nr_13
Maybe you have autosnaps with delzero snaps=yes on the source filesystem -you should not activate this option-
I made sure that delzero was never checked on any of the SANs and could not find a reason for this to fail. I really cant afford to re-seed 3TB over WAN at this point. Is this job salvageable by deleting the mismatched snap pair? I am free to delete snapshots on the source machine as long as they are not replication snaps right?
somehow my replication is already screwed up its first week offsite. The job failed (and didn't alert me via email) with error:
info: 554: incremental zfs receive error after 5 s cannot receive incremental stream: most recent snapshot of pool01-das01/datastore08 does not match incremental source
src snaps: pool01-esx/datastore08@1391145061_repli_zfs_omni-san05_nr_13 -> pool01-esx/datastore08@1391145061_repli_zfs_omni-san05_nr_14
dest: pool01-das01/datastore08 with last snap pool01-esx/datastore08@1391145061_repli_zfs_omni-san05_nr_13
Maybe you have autosnaps with delzero snaps=yes on the source filesystem -you should not activate this option-
I made sure that delzero was never checked on any of the SANs and could not find a reason for this to fail. I really cant afford to re-seed 3TB over WAN at this point. Is this job salvageable by deleting the mismatched snap pair? I am free to delete snapshots on the source machine as long as they are not replication snaps right?
Hey _Gea, I deleted some snaps yesterday because I am doing a lot of moving of VMs and they were taking up a ton of space. In the GUI they do not display, but if I do 'zfs list -r -t snapshot' I see the 3 snaps I deleted.
A) is it safe to just delete these from a shell?
B) any reason why these would not show in the UI?
A) is it safe to just delete these from a shell?
B) any reason why these would not show in the UI?
Hey _Gea, I deleted some snaps yesterday because I am doing a lot of moving of VMs and they were taking up a ton of space. In the GUI they do not display, but if I do 'zfs list -r -t snapshot' I see the 3 snaps I deleted.
A) is it safe to just delete these from a shell?
B) any reason why these would not show in the UI?
- There is no problem if you delete snaps manually at CLI (beside replication snaps)
- The same command 'zfs list -r -t snapshot' I is used by napp-it, so the result should be the same.
Gea,
somehow my replication is already screwed up its first week offsite. The job failed (and didn't alert me via email) with error:
info: 554: incremental zfs receive error after 5 s cannot receive incremental stream: most recent snapshot of pool01-das01/datastore08 does not match incremental source
src snaps: pool01-esx/datastore08@1391145061_repli_zfs_omni-san05_nr_13 -> pool01-esx/datastore08@1391145061_repli_zfs_omni-san05_nr_14
dest: pool01-das01/datastore08 with last snap pool01-esx/datastore08@1391145061_repli_zfs_omni-san05_nr_13
Maybe you have autosnaps with delzero snaps=yes on the source filesystem -you should not activate this option-
I made sure that delzero was never checked on any of the SANs and could not find a reason for this to fail. I really cant afford to re-seed 3TB over WAN at this point. Is this job salvageable by deleting the mismatched snap pair? I am free to delete snapshots on the source machine as long as they are not replication snaps right?
If you start an incremental replication, you create a new source snap snap ex nr_14 and transfer the difference between _13 and _14 to the destination system. This requires that on source and target the nr_13 must be identical as the source is resetted to this snap prior transfer. If and only if the transfer is successful, you have a new snap nr_14 on the target system.
If zfs receive detects, that the common base snap nr_13 is not identical, it cannot proceed and cancels with your error. In such a case you must either redo an initial replication or if you have a snap nr_12 on both sides, you can delete the snap_13 and retry the incremental replication.
A unwanted snap modification can happen if a snap next to the replication snap is deleted ex a zero snap so you must be careful when deleting snaps. If you need a snap history with replications, you can use the keep/hold mechanism for replication jobs to keep target snaps.
- There is no problem if you delete snaps manually at CLI (beside replication snaps)
- The same command 'zfs list -r -t snapshot' I is used by napp-it, so the result should be the same.
Interestingly enough the system and the UI are different. I can upload some screenshots if it would make a difference. It's nothing major, but it could cause someone to run lower on space if they encounter the same thing.
Interestingly enough the system and the UI are different. I can upload some screenshots if it would make a difference. It's nothing major, but it could cause someone to run lower on space if they encounter the same thing.
You can send the screenshots (snaps and zfslist from napp-it and cli) to [email protected] so I can fix it if there is a bug
If you want to check yourself
Its in /var/web-gui/data/napp-it/zfsos/_lib/illumos/zfslib.pl (0.9E2L)
in function sub zfslib_list_datasnaps
Don't remember the exact command sequence, but the gist is: use format command then using the fdisk subcommand create a solaris2 using 100% of the disk. save using option 6 and then do the 'partition' subcommand to create a slice zero using say 90% of the top-level partition. Then 'zpool add tank cXtYdZs0.
Thanks. I'll give it a go.
Meanwhile, another question. The easiest way for me to set up, and what I have done in the past, is to use COMSTAR iSCSI connected to a Mac Pro with 10GbE. Works great.
But, now that I'm redoing everything (again), I'm wondering how would be best to share my storage. Questions:
1. Are there inherent weaknesses to using iSCSI as it regards data integrity? I know there are issues regarding ZFS snapshots, etc, and that there may be performance differences, but I wonder if the data integrity suffers at all. Anyone?
2. If using CIFS/SMB, there are two choices: built-in CIFS and add-on Samba 4.1.x. CIFS would certainly be easier. What I'm concerned about is performance. AFAIK, CIFS does not support SMB v2 or higher. I understand that v2 is a dramatic speed increase over v1. Presumably to get v2, I'd have to use Samba. I am using OS X Mavericks, which defaults to v2.
2a. Does anyone have experience or an opinion on speed of CIFS vs Samba 4.1.x using SMB v2?
2b. If the speed is much better using Samba, any other complications or downsides to be aware of using that instead of CIFS?
Thanks again.
1. No, as Comstar iSCSI is done on ZFS files or ZFS volumes with all ZFS features
Only thing you must know. If you need secure sync write you must disable writeback. If you want to optimize performance you must enable. This is the same like the sync ZFS property for regular writes.
The only thing that depends on snaps. A iSCSI Zvol snap is a snap of the whole device. You can only restore or clone the whole device not single files like with NFS or SMB unless you use features of the guest OS (Windows shadow copies or Apple Timemachine). But that is not a real problem as a ZFS snap include only modified datablock regardless if it is a snap of a 100TB iSCSI device - a huge advantage say over TimeMachine.
2/3. I have not done tests with Windows 8 as an client where it may differ and SMB2 may have performance advantages. Up to now, CIFS was faster than Samba and more "Windows compatible".
The problem with Macs was the SMB stack by Apple where SMB performance is often at 50% of the Windows performance. I have not heard that they improved this with 10.9 beside that Apple plans to replace AFP for SMB as default protocol.
At the moment iSCSI is the fastest followed by NFS for Macs. SMB is the protocol of choice regarding features but slow on Macs. If you do not need user access restrictions, prefer NFS (or ISCSI if you need HFS features)
Info:
Nexenta plans to add SMB2 in their next NexentaStor 4 with a good chance that it will be included into free Illumos as well.
see http://www.listbox.com/member/archi...9081334:59693F4C-68AF-11E3-BCF4-FB8B44C0AD2B/ and following like http://www.listbox.com/member/archive/182180/2013/12/sort/time_rev/page/1/entry/24:53/
Only thing you must know. If you need secure sync write you must disable writeback. If you want to optimize performance you must enable. This is the same like the sync ZFS property for regular writes.
The only thing that depends on snaps. A iSCSI Zvol snap is a snap of the whole device. You can only restore or clone the whole device not single files like with NFS or SMB unless you use features of the guest OS (Windows shadow copies or Apple Timemachine). But that is not a real problem as a ZFS snap include only modified datablock regardless if it is a snap of a 100TB iSCSI device - a huge advantage say over TimeMachine.
2/3. I have not done tests with Windows 8 as an client where it may differ and SMB2 may have performance advantages. Up to now, CIFS was faster than Samba and more "Windows compatible".
The problem with Macs was the SMB stack by Apple where SMB performance is often at 50% of the Windows performance. I have not heard that they improved this with 10.9 beside that Apple plans to replace AFP for SMB as default protocol.
At the moment iSCSI is the fastest followed by NFS for Macs. SMB is the protocol of choice regarding features but slow on Macs. If you do not need user access restrictions, prefer NFS (or ISCSI if you need HFS features)
Info:
Nexenta plans to add SMB2 in their next NexentaStor 4 with a good chance that it will be included into free Illumos as well.
see http://www.listbox.com/member/archi...9081334:59693F4C-68AF-11E3-BCF4-FB8B44C0AD2B/ and following like http://www.listbox.com/member/archive/182180/2013/12/sort/time_rev/page/1/entry/24:53/
Last edited:
If you start an incremental replication, you create a new source snap snap ex nr_14 and transfer the difference between _13 and _14 to the destination system. This requires that on source and target the nr_13 must be identical as the source is resetted to this snap prior transfer. If and only if the transfer is successful, you have a new snap nr_14 on the target system.
If zfs receive detects, that the common base snap nr_13 is not identical, it cannot proceed and cancels with your error. In such a case you must either redo an initial replication or if you have a snap nr_12 on both sides, you can delete the snap_13 and retry the incremental replication.
A unwanted snap modification can happen if a snap next to the replication snap is deleted ex a zero snap so you must be careful when deleting snaps. If you need a snap history with replications, you can use the keep/hold mechanism for replication jobs to keep target snaps.
I believe that if there is a change at the destination then the incremental snapshot will fail. There is a 'force' option that causes the destination to roll back to the necessary snapshot before receiving the incremental update.
pcd
GreatOcean
n00b
- Joined
- Sep 11, 2013
- Messages
- 45
Regarding OmniOS I have met some bizarre issue I can't wrap my head around, anyone seen anything like this and/ or resolved it? I'm stumped and I don't know what to do, post here
http://hardforum.com/showthread.php?t=1805151
Regards,
GreatOcean
http://hardforum.com/showthread.php?t=1805151
Regards,
GreatOcean
Regarding OmniOS I have met some bizarre issue I can't wrap my head around, anyone seen anything like this and/ or resolved it? I'm stumped and I don't know what to do, post here
http://hardforum.com/showthread.php?t=1805151
Regards,
GreatOcean
I also have seen this twice last year.
Seems produced by client problems that force a smbd service restart and not server problems (beside the reaction could be smarter).
see https://www.illumos.org/issues/3646
GreatOcean
n00b
- Joined
- Sep 11, 2013
- Messages
- 45
I also have seen this twice last year.
Seems produced by client problems that force a smbd service restart and not server problems (beside the reaction could be smarter).
see https://www.illumos.org/issues/3646
Ah, good, those dumps made me worried. Will start investigating client by client then and see where I end up.
")
If you plan to browse Maverick's shares from Windows machine,you will end installing Samba at the Mac OSThanks. I'll give it a go.
Meanwhile, another question. The easiest way for me to set up, and what I have done in the past, is to use COMSTAR iSCSI connected to a Mac Pro with 10GbE. Works great.
But, now that I'm redoing everything (again), I'm wondering how would be best to share my storage. Questions:
1. Are there inherent weaknesses to using iSCSI as it regards data integrity? I know there are issues regarding ZFS snapshots, etc, and that there may be performance differences, but I wonder if the data integrity suffers at all. Anyone?
2. If using CIFS/SMB, there are two choices: built-in CIFS and add-on Samba 4.1.x. CIFS would certainly be easier. What I'm concerned about is performance. AFAIK, CIFS does not support SMB v2 or higher. I understand that v2 is a dramatic speed increase over v1. Presumably to get v2, I'd have to use Samba. I am using OS X Mavericks, which defaults to v2.
2a. Does anyone have experience or an opinion on speed of CIFS vs Samba 4.1.x using SMB v2?
2b. If the speed is much better using Samba, any other complications or downsides to be aware of using that instead of CIFS?
Thanks again.
.Browsing Mac's 10.9 shares from Windows 7/8 is PITA,just not working. The only one workaround which i found ,besides third party tools , is to disable smb v2/3 in Windows .
SmbUP do the job for me.
brutalizer
[H]ard|Gawd
- Joined
- Oct 23, 2010
- Messages
- 1,602
Both Oracle ZFS and OpenZFS has TRIM support for SSDs now.
If you start an incremental replication, you create a new source snap snap ex nr_14 and transfer the difference between _13 and _14 to the destination system. This requires that on source and target the nr_13 must be identical as the source is resetted to this snap prior transfer. If and only if the transfer is successful, you have a new snap nr_14 on the target system.
If zfs receive detects, that the common base snap nr_13 is not identical, it cannot proceed and cancels with your error. In such a case you must either redo an initial replication or if you have a snap nr_12 on both sides, you can delete the snap_13 and retry the incremental replication.
A unwanted snap modification can happen if a snap next to the replication snap is deleted ex a zero snap so you must be careful when deleting snaps. If you need a snap history with replications, you can use the keep/hold mechanism for replication jobs to keep target snaps.
Thanks gea, I was under the impression i could delete any snaps that weren't replication snaps on the source filesystem. Are you saying that i cant delete ANY snaps on the source filesystem as it might screw up replication?
HammerSandwich
[H]ard|Gawd
- Joined
- Nov 18, 2004
- Messages
- 1,126
Couldn't you compare the 2 incrementals' sizes?ZFS send/receive does not offer progress informations. For the initial transfer I compare the size of the source filesystem vs the target one. For incremental transfers there is no similar workaround.
Couldn't you compare the 2 incrementals' sizes?
i think the issue here is that the destination snap is only created AFTER all the data has been successfully transferred.
Thanks gea, I was under the impression i could delete any snaps that weren't replication snaps on the source filesystem. Are you saying that i cant delete ANY snaps on the source filesystem as it might screw up replication?
I would be at least careful with deleting zero sized snaps next to a replication snap.
HammerSandwich
[H]ard|Gawd
- Joined
- Nov 18, 2004
- Messages
- 1,126
I thought the source had both snaps at the start.i think the issue here is that the destination snap is only created AFTER all the data has been successfully transferred.
Question on doing backups using zfs send.
My plan is to have an HP Microserver that I normally keep offsite but bring onsite once a week or so to get a backup of my production server. My problem is that I was planning to have just one ZFS volume on the production server. The size of the volume will be larger than what my Microserver can hold. The thought was to possibly have two Microservers, one with data that isn't changing anymore and the other with constantly updated data. For me, that is defined by directories (some are old and stagnant, some are current and frequently changing).
So my question is, without having multiple ZFS volumes, is there any way to send only certain directories within a volume?
Regarding my previous posts, I have backed off using SSDs for the pool for now. They were not going to provide the size I needed plus there are the lingering doubts about using consumer-grade SSDs with no capacitors. Not to mention the cost. So I just decided to skip it for now.
My plan is to have an HP Microserver that I normally keep offsite but bring onsite once a week or so to get a backup of my production server. My problem is that I was planning to have just one ZFS volume on the production server. The size of the volume will be larger than what my Microserver can hold. The thought was to possibly have two Microservers, one with data that isn't changing anymore and the other with constantly updated data. For me, that is defined by directories (some are old and stagnant, some are current and frequently changing).
So my question is, without having multiple ZFS volumes, is there any way to send only certain directories within a volume?
Regarding my previous posts, I have backed off using SSDs for the pool for now. They were not going to provide the size I needed plus there are the lingering doubts about using consumer-grade SSDs with no capacitors. Not to mention the cost. So I just decided to skip it for now.
Hoping someone has any ideas for me, yesterday my storage pool was online and suddenly cut out on me. Decided to let it go for the night thinking maybe it just needed to clear up a cache. today i logged into napp-it and see that the entire pool is marked as unavailable. I can see the drives blink on like system start and thats the end of it. i have an M1015 in IT mode, with an intel RVS..... sas expander that has worked great for a couple years now. Solaris express 11 (i would convert but i had upgraded ZFS pools )
)So my question is, without having multiple ZFS volumes, is there any way to send only certain directories within a volume?
No, not with zfs send that replicates filesystems.
You may use rsync that can sync files and folders
btw.
What you mean with volumes?
- a ZFS pool like Nexenta
- a ZFS filesystem
- a ZFS zvol
Hoping someone has any ideas for me, yesterday my storage pool was online and suddenly cut out on me. Decided to let it go for the night thinking maybe it just needed to clear up a cache. today i logged into napp-it and see that the entire pool is marked as unavailable. I can see the drives blink on like system start and thats the end of it. i have an M1015 in IT mode, with an intel RVS..... sas expander that has worked great for a couple years now. Solaris express 11 (i would convert but i had upgraded ZFS pools
In case of a blocking disk, i would first power off/on the whole system
tried that, actually got it to respond by moving one of the connections from the SAS expander directly to the SAS card. But its showing failed drives . I guess when i get money sometime soon its time to do some HDD replacements as i've got 3 failed now.
. I guess when i get money sometime soon its time to do some HDD replacements as i've got 3 failed now.No, not with zfs send that replicates filesystems.
You may use rsync that can sync files and folders
btw.
What you mean with volumes?
- a ZFS pool like Nexenta
- a ZFS filesystem
- a ZFS zvol
Is there a downside to rsync? Is data integrity just as good? Sorry for my terminology, I meant "ZFS filesystem".
Thanks!
TeeJayHoward
Limpness Supreme
- Joined
- Feb 8, 2005
- Messages
- 12,268
Well, I figured out the NFS permissions issue, now SMB permissions don't work. All of these lovely ACLs refuse to recurse. You would think that this:

...would be enough to let a user write to the share, but no. Read-only.
I tried going to ZFS Filesystems -> acl extension -> ACL on folders and using "reset ACL's".
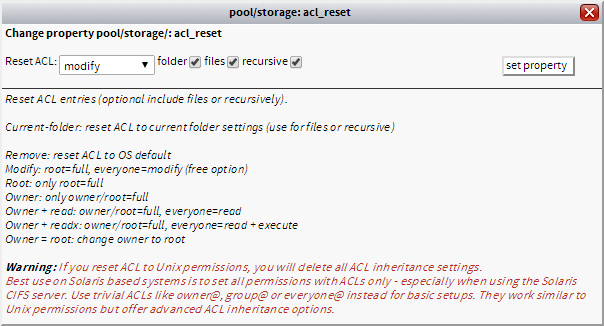
See that "recursive" box? When checked, it does NOT alter the permissions of folders and files underneath that level for some reason. This is driving me freaking bonkers. I've never had this much issue with an SMB share! It doesn't appear that any change I make affects anything but the top level of folders, and with hundreds of thousands of files, there's no freaking way I'm going to change them all by hand!
What am I doing wrong?
...would be enough to let a user write to the share, but no. Read-only.
I tried going to ZFS Filesystems -> acl extension -> ACL on folders and using "reset ACL's".
See that "recursive" box? When checked, it does NOT alter the permissions of folders and files underneath that level for some reason. This is driving me freaking bonkers. I've never had this much issue with an SMB share! It doesn't appear that any change I make affects anything but the top level of folders, and with hundreds of thousands of files, there's no freaking way I'm going to change them all by hand!
What am I doing wrong?
TeeJayHoward
Limpness Supreme
- Joined
- Feb 8, 2005
- Messages
- 12,268
What the HELL?
OmniOS decided to mimic a Solaris OS, but uses GNU commands instead of their Solaris counterparts? Seriously. What. The. Hell.
getfacl/setfacl don't work on ZFS. But they're included! No, for ZFS, you're supposed to use "ls -v" and "chmod" to get and set ACLs. So why the HELL did they decide to replace those commands with ones that don't have that functionality? Thank god they're still there in /bin, or I would have thrown the whole OS out the window and gone back to Solaris 11.1.
Jesus, and people wonder why Open-Source Solaris isn't taking off. It's crap like this that's killing it.
OmniOS decided to mimic a Solaris OS, but uses GNU commands instead of their Solaris counterparts? Seriously. What. The. Hell.
getfacl/setfacl don't work on ZFS. But they're included! No, for ZFS, you're supposed to use "ls -v" and "chmod" to get and set ACLs. So why the HELL did they decide to replace those commands with ones that don't have that functionality? Thank god they're still there in /bin, or I would have thrown the whole OS out the window and gone back to Solaris 11.1.
Jesus, and people wonder why Open-Source Solaris isn't taking off. It's crap like this that's killing it.
TeeJayHoward
Limpness Supreme
- Joined
- Feb 8, 2005
- Messages
- 12,268
While my ACLs get removed, I encountered another issue!

Note the SMB: off?
Yeah... I can still access the share via Windows.
edit: Turns out I needed to restart the SMB service.
svcadm restart svc:/network/smb/server:default
Note the SMB: off?
Yeah... I can still access the share via Windows.
edit: Turns out I needed to restart the SMB service.
svcadm restart svc:/network/smb/server:default
Last edited:
TeeJayHoward
Limpness Supreme
- Joined
- Feb 8, 2005
- Messages
- 12,268
Aah, so that's a napp-it thing, not an OmniOS thing. Good to know.teejay, did you install napp-it? if so, it put gnu command in a different place that gets searched first. i got bit by this too...
I took a break from this project for a few hours, played some Final Fantasy. Ready to re-tackle it. Why the heck can't I write to my SMB share?
Edit: Fixed it, I guess. Or at least found a workaround.
idmap add 'winuser:[email protected]' 'unixuser:root'
idmap add 'wingroup:administrators' 'unixgroup:root'
Log in to the CIFS share from a Windows box with "[email protected]" as the username, and the password for that account. Previously, I was using "winuser:administrator", and it wasn't working. The domain had to be in there for it to function. I do still have guestok=on or true or whatever that setting is. Looks like a little break was all I needed.
Last edited:
What the HELL?
OmniOS decided to mimic a Solaris OS, but uses GNU commands instead of their Solaris counterparts? Seriously. What. The. Hell.
getfacl/setfacl don't work on ZFS. But they're included! No, for ZFS, you're supposed to use "ls -v" and "chmod" to get and set ACLs. So why the HELL did they decide to replace those commands with ones that don't have that functionality? Thank god they're still there in /bin, or I would have thrown the whole OS out the window and gone back to Solaris 11.1.
Jesus, and people wonder why Open-Source Solaris isn't taking off. It's crap like this that's killing it.
This is the Solaris default and a behaviour inherited from OpenSolaris and used since then even in Oracle Solaris and not a special thing with Illumos based systems or napp-it.
You can modify your default path in /root.profile or use the Solaris versions like /usr/bin/chmod instead of a pure chmod.
See that "recursive" box? When checked, it does NOT alter the permissions of folders and files underneath that level for some reason. This is driving me freaking bonkers. I've never had this much issue with an SMB share! It doesn't appear that any change I make affects anything but the top level of folders, and with hundreds of thousands of files, there's no freaking way I'm going to change them all by hand!
What am I doing wrong?
With the combined Linux/Solaris Version there is a path bug resulting in ACL set-problems or an error in menu ZFS filesystems - ACL on folders.
I have fixed the basic problem with newest 0.9e2L preview but need to do some tests to check if this was the only problem. This is due the need for different libraries for Solaris and Linux.
For basic permission settings (without deny rules) you can connect from Windows as root and reset ACL from there recursively.
Is there a downside to rsync? Is data integrity just as good?
Thanks!
zfs send especially over netcat or mbuffer is much faster than rsync. Main extra problem is the inability of rsync to copy ZFS properties like ACL
If you like to rsync open files you must use snaps as source as well.