Lot of words, little substance. The Vega reveal was clear enough. The changes were extensive and chip wide with added major functions new to GPUs. To call these changes 'trivial' implies what AMD said is mostly lies and propaganda. What calling these changes 'trivial' implies about the poster I'll leave unsaid.
There is a ton of substance in my post, I suggest you look up the async threads to figure out I'm not making things up. I don't have the patience to explain those things to someone who isn't bothered by reading......
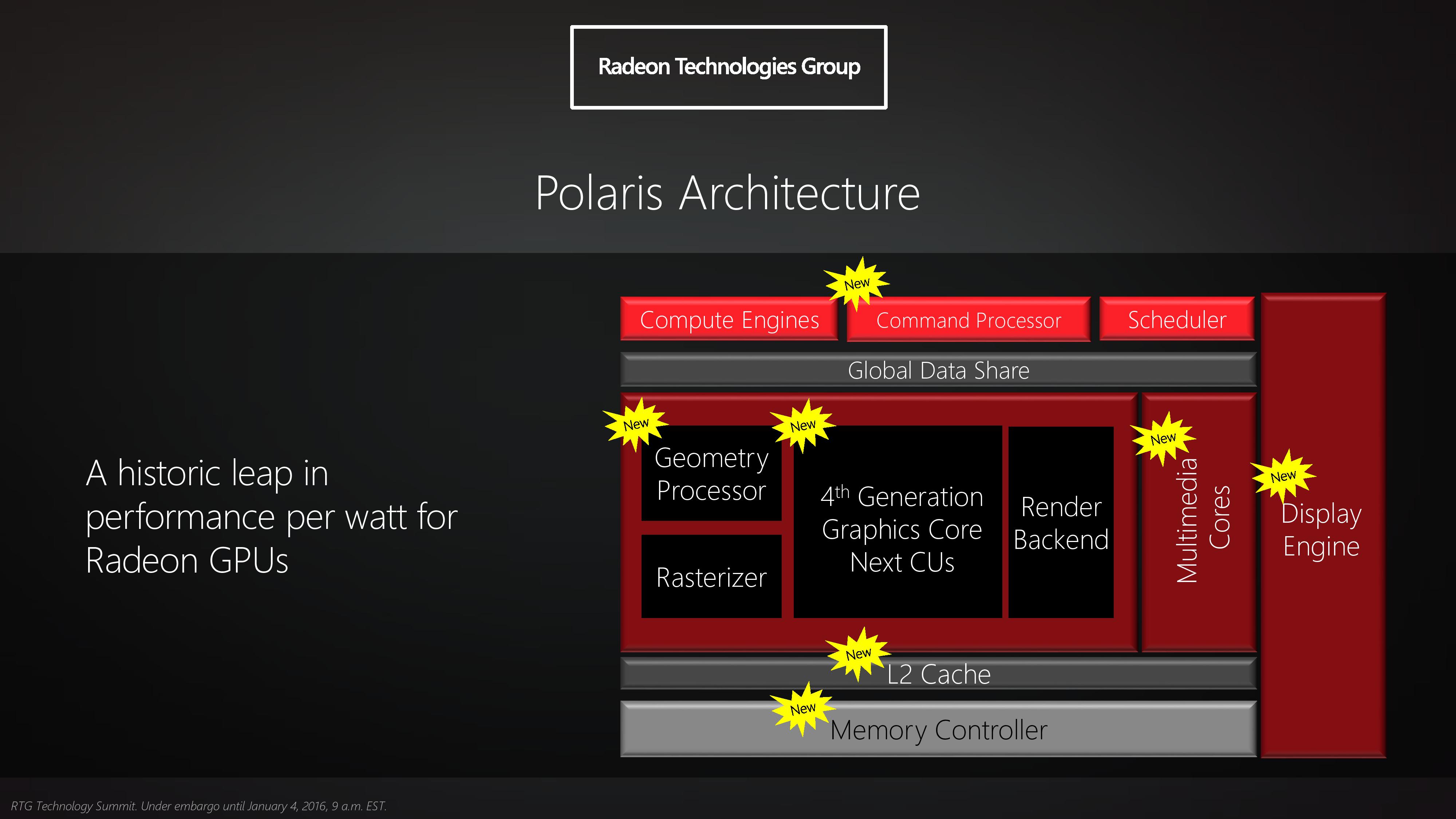
You don't understand the different parts of a GPU, you don't know what Async compute is or how it functions at a GPU architectural level, you don't know how the polygon throughput improvements in Polaris show up outside of synthetics and when we do look at synthetics they only match a gtx 960.... which is 2x the geometry through put of Fiji.
You don't sit here and make crap up based on AMD marketing that has shown so many times they are incapable of keeping things realistic when you look at final "projected" best case numbers.
Everything AMD states has truth in it, how much truth is face value, don't extrapolate off that cause you will be disappointed. If they say something, its always best case, in most cases its lower, I can show you interviews about the changes in Vega about polygon through put and the TBR and primitive discard in conjunction with primitive shaders where best case is 11 polys discard which is the 4x polygon through put in best cases if not using primitive shaders 2.5x over Fiji, guess what, that is just a bit higher than Polaris, not too much though based on synthetics that we know for sure.
Red gaming tech on youtube has an interview with Scott Wasson about these things so be my guest and look it up if you like, AMD's own people aren't making the things up, they are being straight about it, yet you are believing in the highest possible performance increases without understanding the limitations of what they are saying are. And there are specific limitations.
What you are posting is apparently you know more then any other reviewer about Aysnc compute, any other programmer about it, or AMD empolyees about Vega?
Either you are making shit up because of what ever reason, or what I'm hearing here, is what I've been saying, you can't use the higher level features of Vega which are the numbers Vega had up in their word cloud, are going to need to use primitive shaders. Unlike all the polygon through put increases nV has done or their tiled rasterizer which are just automatic.
So pretty much Vega couldn't fixed the issues they had with its geometry pipeline, they are now telling dev's code it for their array. Which goes to show you anything to do with that will not work automagically. Cause AMD will need to release an SDK or API that include those extensions otherwise they can't be accessed. Ironically, games that are part of AMD's game dev program (one for sure Dice's engine) already do this in code lol. There has been culling examples in interviews and power point presentations by Dice which they mentioned this in conjunction with Mantle and later DX12 for AMD hardware for primitive discard!
Last edited:





") There is more then just geometry to worry about in other words.
There is more then just geometry to worry about in other words.