Hi All,
Looking to implement a home ZFS NAS/SAN in the near future to be used to serve a Hyper-V failover cluster via iSCSI.
I was originally planning to use 4 x 1TB WD Black SATA drives. The pool would consist of two mirrors of two drives.
I would use a low cost 32 or 64GB SSD for the L2ARC and a 4 or 8GB SSD for the ZIL.
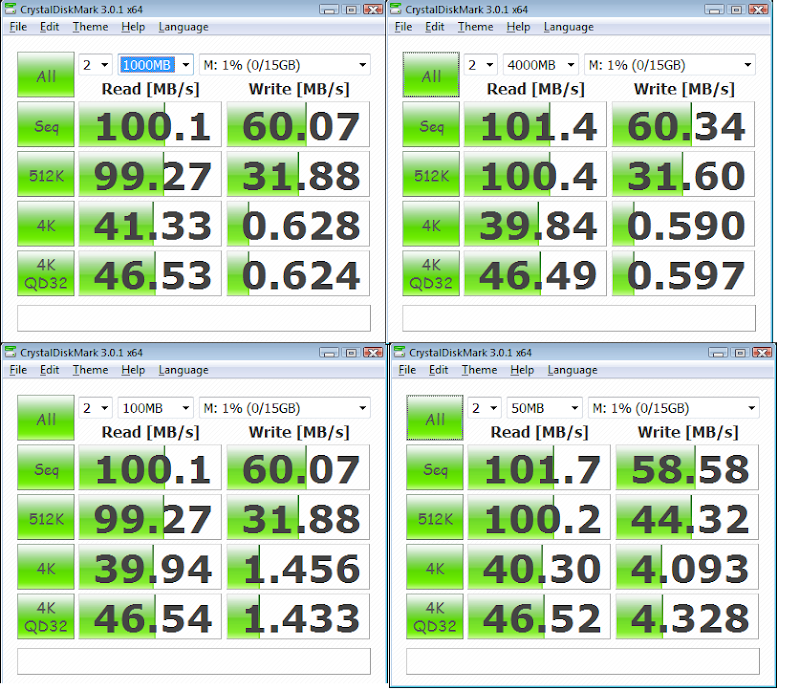
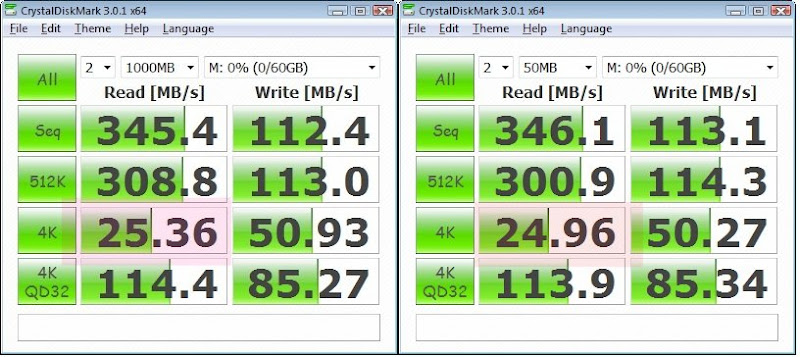
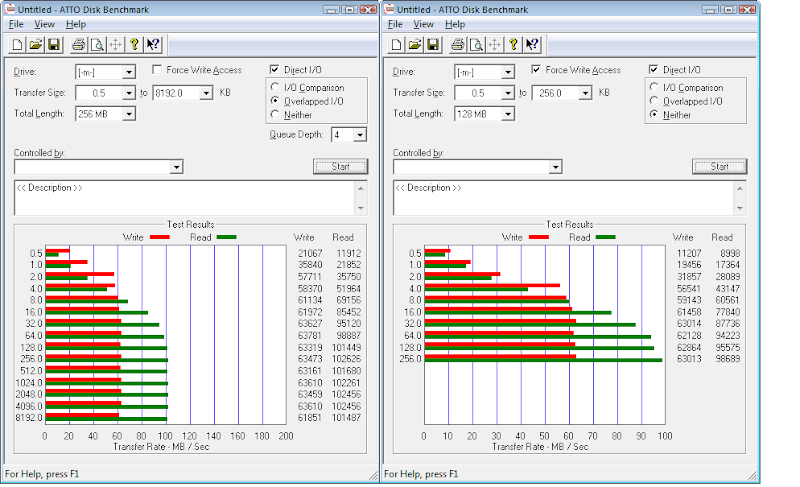
However, I am unsure about the SSD for the ZIL. It's my understanding that any writes would first have to pass through the ZIL before being committed to disk. Does this mean that write performance for the whole pool is limited to the write speed of your ZIL device?
Thanks!!
Riley
Looking to implement a home ZFS NAS/SAN in the near future to be used to serve a Hyper-V failover cluster via iSCSI.
I was originally planning to use 4 x 1TB WD Black SATA drives. The pool would consist of two mirrors of two drives.
I would use a low cost 32 or 64GB SSD for the L2ARC and a 4 or 8GB SSD for the ZIL.
However, I am unsure about the SSD for the ZIL. It's my understanding that any writes would first have to pass through the ZIL before being committed to disk. Does this mean that write performance for the whole pool is limited to the write speed of your ZIL device?
Thanks!!
Riley